Dónde están nuestros datos en el disco?
Table Of Contents
Al final del día, una base de datos tiene toda la información que necesita para funcionar grabada en nuestro disco duro. PostgreSQL no es una excepción.
En este artículo vamos a intentar dar una introducción sobre como PostgreSQL 9.1 graba nuestros datos en el disco y como se las arregla para encontrar los mismos cuando los necesitamos. Tener las cosas claras en lo que respecta a este tema nos puede ayudar en momentos difíciles como administradores de bases de datos, en el caso que nuestros datos se corrompan por alguna causa.
Organizacion en el disco
Para empezar vamos a ver como PostgreSQL organiza los ficheros con nuestros datos en el disco. Todos los ficheros usados por PostgreSQL se encuentran en el directorio que hayamos definido como directorio de datos (data_directory) en nuestro sistema.
postgres=# SHOW data_directory;
data_directory
----------------
/var/pgsql
(1 row)
Dentro del directorio de datos encontraremos varios subdirectorios con diferentes cometidos.
postgres@server01:~$ cd /var/pgsql/
postgres@server01:/var/pgsql$ ls -l
total 92
drwx------ 7 postgres nogroup 4096 2011-10-04 18:01 base
drwx------ 2 postgres nogroup 4096 2011-10-04 18:24 global
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_clog
-rw------- 1 postgres nogroup 4476 2011-10-04 17:53 pg_hba.conf
-rw------- 1 postgres nogroup 1636 2011-10-04 17:53 pg_ident.conf
drwx------ 4 postgres nogroup 4096 2011-10-04 17:53 pg_multixact
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_notify
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_serial
drwx------ 2 postgres nogroup 4096 2011-10-05 11:23 pg_stat_tmp
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_subtrans
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_tblspc
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 pg_twophase
-rw------- 1 postgres nogroup 4 2011-10-04 17:53 PG_VERSION
drwx------ 3 postgres nogroup 4096 2011-10-04 17:53 pg_xlog
-rw------- 1 postgres nogroup 19129 2011-10-04 17:53 postgresql.conf
-rw------- 1 postgres nogroup 42 2011-10-04 17:53 postmaster.opts
-rw------- 1 postgres nogroup 68 2011-10-04 17:53 postmaster.pid
El que nos interesa en este artículo es uno que se llama base. Dentro de este subdirectorio se graban todos los datos contenidos en nuestras bases de datos.
En el sistema utilizado para este artículo tenemos lo siguiente en este directorio:
postgres@server01:/var/pgsql$ ls -l base/
total 28
drwx------ 2 postgres nogroup 12288 2011-10-04 17:53 1
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 11939
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 11947
Como podeis ver, dentro del subdirectorio base existen otros subdirectorios com nombres numéricos. Cada subdirectorio dentro del directorio base, es una base de datos diferente. Para saber a que base de datos corresponden estos subdirectorios podeis ejecutar este comando SQL en vuestro cliente:
postgres=# SELECT datid,datname from pg_stat_database;
datid | datname
-------+-----------
1 | template1
11939 | template0
11947 | postgres
(5 rows)
Los valores en la columna datid, corresponden a los valores listados en el subdirectorio base y la columna datname es el nombre de la base de datos asociada al identificador numérico.
Vamos a crear una base de datos para nuestros ejemplos y a ver como esto afecta a nuestro sistema.
postgres=# CREATE DATABASE testing_internals;
CREATE DATABASE
Podemos ver como se ha creado un nuevo subdirectorio con el nombre 16407, correspondiente a la nueva base de datos creada.
postgres@server01:/var/pgsql$ ls -l base/
total 24
drwx------ 2 postgres nogroup 12288 2011-10-04 17:53 1
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 11939
drwx------ 2 postgres nogroup 4096 2011-10-04 17:53 11947
drwx------ 2 postgres nogroup 4096 2011-10-05 11:31 16407
postgres=# SELECT datid,datname from pg_stat_database;
datid | datname
-------+-------------------
1 | template1
11939 | template0
11947 | postgres
16407 | testing_internals
(4 rows)
Si haceis un listado de este nuevo subdirectorio vereis que ya tiene una serie de ficheros aunque no hayais creado ninguna tabla todavía. Estos ficheros pertenecen al sistema y son necesarios para que la base de datos que habeis creado funcione. Para este artículo no necesitamos saber nada más sobre los mismos, solo que estan ahí y que son necesarios.
Ahora creamos una tabla muy simple en nuestra base de datos con un par de columnas de tipo integer:
postgres=# \c testing_internals
You are now connected to database "testing_internals" as user "postgres".
testing_internals=# CREATE TABLE test001 ( id INTEGER, code INTEGER, primary key(id));
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "test001_pkey" for table "test001"
CREATE TABLE
testing_internals=# \d test001
Table "public.test001"
Column | Type | Modifiers
--------+---------+-----------
id | integer | not null
code | integer |
Indexes:
"test001_pkey" PRIMARY KEY, btree (id)
El identificador de la tabla test001 y el fichero correspondiente lo podemos obtener por ejemplo de esta manera:
testing_internals=# SELECT pg_relation_filenode('test001'),pg_relation_filepath('test001');
pg_relation_filenode | pg_relation_filepath
----------------------+----------------------
16465 | base/16407/16465
(1 row)
Y el del índice test001_pkeycreado para clave primaria de esta tabla con:
testing_internals=# SELECT pg_relation_filenode('test001_pkey'),pg_relation_filepath('test001_pkey');
pg_relation_filenode | pg_relation_filepath
----------------------+----------------------
16468 | base/16407/16468
(1 row)
Si hacemos un listado del contenido del directorio de nuestra base de datos (base/16407) podremos ver que se han creado dos nuevos ficheros con los nombres 16465 y 16468.
postgres@server01:/var/pgsql$ ls -l base/16407/16465
-rw------- 1 postgres nogroup 0 2011-10-06 12:09 base/16407/16465
postgres@server01:/var/pgsql$ ls -l base/16407/16468
-rw------- 1 postgres nogroup 8192 2011-10-06 12:09 base/16407/16468
Si esta tabla o índice llegasen a ser mayores que 1GB, se dividirian a nivel del sistema de ficheros en ficheros con un máximo de 1GB cada uno. Si por ejemplo, nuestra tabla llegase a ser de 3,5GB, veriamos algo similar a esto:
[postgres@server]$ ls -l base/16407/16465*
-rw------- 1 postgres pgdba 1073741824 Jul 5 15:11 base/16407/16465
-rw------- 1 postgres pgdba 1073741824 Jul 6 15:11 base/16407/16465.1
-rw------- 1 postgres pgdba 1073741824 Jul 7 15:11 base/16407/16465.2
-rw------- 1 postgres pgdba 536870912 Jul 8 15:11 base/16407/16465.3
Bloques de datos en el disco
Una vez visto como encontrar en nuestro sistema de ficheros nuestras bases de datos con sus tablas e índices, tenemos que saber como se graban nuestros datos en estos ficheros.
Lo primero que tenemos que decir es que la unidad mínima de almacenamiento en PostgreSQL se denomina, indistintamente, página (page) o bloque (block). Un bloque en PostgreSQL ocupa siempre por defecto 8K si no se ha definido un valor diferente durante la compilación. Esto independientemente de si se usa en su totalidad o solo parcialmente.
A continuación vamos a ver como se divide internamente el espacio en una página o bloque:
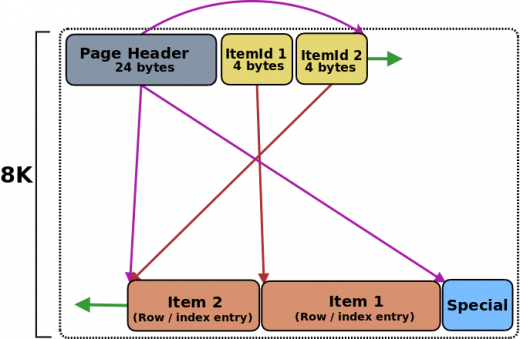
Un bloque (8K / 8192 bytes) está compuesto por diferentes elementos:
- Page_header: Cabecera de bloque. Ocupa 24 bytes.
- ItemId: Matriz de pares de valores ItemId(offset,length) con la información necesaria para localizar los elementos (Items) grabados en el bloque. Cada par ocupa 4 bytes.
- Item (row/index): Cabecera de elemento más los datos en si. Tamaño variable.
- Espacio especial: Usado cuando el bloque pertenece a un índice. Tamaño variable
El espacio usado por una cabecera de bloque (Page_header) se usa para guardar diferentes parámetros que nos ayudarán a localizar diferentes partes del bloque y guardar cierta información asociada al bloque.
En cada elemento (Item) se guardan una cabecera de datos con un tamaño fijo (23 bytes), una pequeña cabecera opcional de datos con tamaño variable y los datos en si de nuestras tablas o índices.
Para una completa descripción de estas cabeceras y las estructuras usadas para almacenar los datos en el disco, podeis consultar la documentación y el código fuente. Teneis los enlaces al final del artículo. En este artículo vamos a ver solamente las más relevantes para el mismo.
Obteniendo información de los bloques de datos
Antes de seguir vamos a instalar unos cuantos módulos contrib que se distribuyen con PostgreSQL y que nos servirán de mucha ayuda en este artículo para consultar y analizar la información que tenemos grabada en el disco. A partir de la versión 9.1, podemos instalar estos módulos de manera muy fácil con la nueva funcionalidad CREATE EXTENSION:
postgres=# \c testing_internals
You are now connected to database "testing_internals" as user "postgres".
testing_internals=# CREATE EXTENSION pgstattuple;
CREATE EXTENSION
testing_internals=# CREATE EXTENSION pageinspect;
CREATE EXTENSION
A continuación vamos a insertar algunas filas en nuestra tabla de pruebas test001:
testing_internals=# INSERT INTO test001 (id,code) VALUES (1,100);
INSERT 0 1
testing_internals=# SELECT ctid,* from test001 ;
ctid | id | code
-------+----+------
(0,1) | 1 | 100
(1 row)
El valor ctid(0,1) nos indica que esta fila está en el bloque numero 0 y que es el elemento 1 (Item) en ese bloque.
Ya hemos grabado los primeros datos en nuestra tabla y sabemos que ocupará por defecto 1 bloque 8K. Si listamos el fichero correspondiente a nuestra tabla podemos ver que efectivamente ocupa exactamente 8K. Este fichero seguirá teniendo 8K hasta que utilicemos todo el espacio libre en el mismo con sucesivas actualizaciones de la tabla:
postgres@server01:/var/pgsql$ ls -l base/16407/16465
-rw------- 1 postgres nogroup 8192 2011-10-06 12:30 base/16407/16465
Utilizando una de las funciones disponibles en la extensión pgstattuple, podemos obtener cierta información sobre nuestra tabla:
testing_internals=# SELECT * from pgstattuple('test001');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
8192 | 1 | 32 | 0.39 | 0 | 0 | 0 | 8128 | 99.22
(1 row)
Como podeis ver, los datos corresponden a lo que hemos hecho con la tabla. El tamaño actual de la tabla (table_len) es 8192 bytes (1 bloque), solamente tenemos 1 fila (tuple_count), la única fila que tenemos ocupa 32 bytes (23 bytes de cabeceras fijas + 1 byte de alineación hasta el comienzo de los datos + 4 bytes de la primera columna integer + 4 bytes de la segunda columna), no hay filas muertas y el espacio libre en el bloque es de 8128 bytes.
Usando la extensión pageinspect podemos obtener más información sobre el primer bloque en disco de nuestra tabla. Sabemos que solamente hemos usado un bloque por el valor ctid de nuestra primera y única fila.
Vamos a utilizar las funciones page_header() y heap_page_items() junto con la función get_raw_page() para obtener información sobre los datos disponibles en la cabecera del bloque, en las entradas itemId y en las cabeceras de los elementos (Item):
testing_internals=# SELECT * FROM page_header(get_raw_page('test001', 0));
lsn | tli | flags | lower | upper | special | pagesize | version | prune_xid
-----------+-----+-------+-------+-------+---------+----------+---------+-----------
0/17F7A00 | 1 | 0 | 28 | 8160 | 8192 | 8192 | 4 | 0
(1 row)
testing_internals=# SELECT * FROM heap_page_items(get_raw_page('test001', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 32 | 755 | 0 | 0 | (0,1) | 2 | 2304 | 24 | |
(1 row)
Aquí los datos también corresponden a lo que hemos hecho.
De la cabecera de bloque tenemos el parámetro lower = 28 que nos indica la siguiente posición libre en donde se grabará el próximo itemId. upper = 8160 nos indica el final del espacio libre en el bloque (a partir de esta posición tendremos todos los elementos (Items) grabados en este bloque. special = 8192 indica el principio (offset) del espacio especial (en este caso al ser una tabla y no un índice, special es igual al tamaño de bloque porque el espacio especial esta vacio)
De las entradas itemId (tambien llamadas Line Pointer) y las cabeceras de los elementos (Item), podemos destacar lp = 1 que nos indica que es el itemId número 1, lp_off = 8160 nos indica el inicio (offset) del primer elemento (item), lp_flags = 1 nos indica que el itemId está en uso, lp_len = 32 es el tamaño en bytes del elemento al que el itemId está apuntando, t_xmin = 755 nos indica la transacción en donde este elemento fue creado, t_xmax es la transacción en la que el elemento ha sido borrado (0 en este caso porque todavía no se ha borrado), t_ctid = (0,1) nos dice que este elemento es el primero del bloque 0 en esta tabla y t_hoff = 24 es la posición relativa en donde empezamos a grabar los datos en si de las columnas de la primara fila (la posicion absoluta seria lp_off + t_hoff = 8184).
Con todos estos datos podemos tener mas control sobre donde están nuestros datos grabados y como. Puede que este conocimiento nos ayude en momentos críticos. Vamos a seguir haciendo cambios en nuestra tabla y ver como se van cambiando los valores de los que hemos hablado.
Es un buen ejercicio para ir familiarizandose con el tema. Intentar comprender los valores que van cambiando y porque.
Insertamos un par de filas nuevas:
testing_internals=# INSERT INTO test001 (id,code) VALUES (2,200);
INSERT 0 1
testing_internals=# INSERT INTO test001 (id,code) VALUES (3,300);
INSERT 0 1
testing_internals=# SELECT ctid,* from test001 ;
ctid | id | code
-------+----+------
(0,1) | 1 | 100
(0,2) | 2 | 200
(0,3) | 3 | 300
(3 rows)
testing_internals=# SELECT * from pgstattuple('test001');
```text
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
8192 | 3 | 96 | 1.17 | 0 | 0 | 0 | 8056 | 98.34
(1 row)
testing_internals=# SELECT * FROM page_header(get_raw_page('test001', 0));
lsn | tli | flags | lower | upper | special | pagesize | version | prune_xid
-----------+-----+-------+-------+-------+---------+----------+---------+-----------
0/18BA7F8 | 1 | 0 | 36 | 8096 | 8192 | 8192 | 4 | 0
(1 row)
testing_internals=# SELECT * FROM heap_page_items(get_raw_page('test001', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 32 | 755 | 0 | 0 | (0,1) | 2 | 2304 | 24 | |
2 | 8128 | 1 | 32 | 756 | 0 | 0 | (0,2) | 2 | 2304 | 24 | |
3 | 8096 | 1 | 32 | 846 | 0 | 0 | (0,3) | 2 | 2304 | 24 | |
(3 rows)
Borramos la fila con id = 2.
testing_internals=# DELETE FROM test001 WHERE id = 2;
DELETE 1
testing_internals=# SELECT ctid,* from test001 ;
ctid | id | code
-------+----+------
(0,1) | 1 | 100
(0,3) | 3 | 300
(2 rows)
testing_internals=# SELECT * from pgstattuple('test001');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
8192 | 2 | 64 | 0.78 | 1 | 32 | 0.39 | 8056 | 98.34
(1 row)
testing_internals=# SELECT * FROM page_header(get_raw_page('test001', 0));
lsn | tli | flags | lower | upper | special | pagesize | version | prune_xid
-----------+-----+-------+-------+-------+---------+----------+---------+-----------
0/18BA920 | 1 | 0 | 36 | 8096 | 8192 | 8192 | 4 | 847
(1 row)
testing_internals=# SELECT * FROM heap_page_items(get_raw_page('test001', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 32 | 755 | 0 | 0 | (0,1) | 2 | 2304 | 24 | |
2 | 8128 | 1 | 32 | 756 | 847 | 0 | (0,2) | 2 | 1280 | 24 | |
3 | 8096 | 1 | 32 | 846 | 0 | 0 | (0,3) | 2 | 2304 | 24 | |
(3 rows)
Ejecutamos un VACCUM.
testing_internals=# VACUUM ;
VACUUM
testing_internals=# SELECT * from pgstattuple('test001');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
8192 | 2 | 64 | 0.78 | 0 | 0 | 0 | 8088 | 98.73
(1 row)
testing_internals=# SELECT * FROM page_header(get_raw_page('test001', 0));
lsn | tli | flags | lower | upper | special | pagesize | version | prune_xid
-----------+-----+-------+-------+-------+---------+----------+---------+-----------
0/18C1740 | 1 | 1 | 36 | 8128 | 8192 | 8192 | 4 | 0
(1 row)
testing_internals=# SELECT * FROM heap_page_items(get_raw_page('test001', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 32 | 755 | 0 | 0 | (0,1) | 2 | 2304 | 24 | |
2 | 0 | 0 | 0 | | | | | | | | |
3 | 8128 | 1 | 32 | 846 | 0 | 0 | (0,3) | 2 | 2304 | 24 | |
(3 rows)
Volvemos a introducir otra fila.
testing_internals=# SELECT ctid,* from test001 ;
ctid | id | code
-------+----+------
(0,1) | 1 | 100
(0,2) | 4 | 400
(0,3) | 3 | 300
(3 rows)
testing_internals=# INSERT INTO test001 (id,code) VALUES (4,400);
INSERT 0 1
testing_internals=# SELECT * from pgstattuple('test001');
table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent
-----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+--------------
8192 | 3 | 96 | 1.17 | 0 | 0 | 0 | 8056 | 98.34
(1 row)
testing_internals=# SELECT * FROM page_header(get_raw_page('test001', 0));
lsn | tli | flags | lower | upper | special | pagesize | version | prune_xid
-----------+-----+-------+-------+-------+---------+----------+---------+-----------
0/18C1870 | 1 | 1 | 36 | 8096 | 8192 | 8192 | 4 | 0
(1 row)
testing_internals=# SELECT * FROM heap_page_items(get_raw_page('test001', 0));
lp | lp_off | lp_flags | lp_len | t_xmin | t_xmax | t_field3 | t_ctid | t_infomask2 | t_infomask | t_hoff | t_bits | t_oid
----+--------+----------+--------+--------+--------+----------+--------+-------------+------------+--------+--------+-------
1 | 8160 | 1 | 32 | 755 | 0 | 0 | (0,1) | 2 | 2304 | 24 | |
2 | 8096 | 1 | 32 | 848 | 0 | 0 | (0,2) | 2 | 2304 | 24 | |
3 | 8128 | 1 | 32 | 846 | 0 | 0 | (0,3) | 2 | 2304 | 24 | |
(3 rows)
Seguir “jugando” y probando cosas e intentar familiarizaros con el tema. Han quedado varias cosas en el tintero, como por ejemplo, como interpretar estos datos con índices o con columnas de tamaño variable y valores TOAST. Más adelante intentaremos hablar del tema.
En un próximo artículo veremos como podremos aplicar lo que hemos aprendido en este artículo en la vida real.
Enlaces:
- http://www.postgresql.org/docs/current/interactive/storage-file-layout.html
- http://www.postgresql.org/docs/current/interactive/storage-page-layout.html
- http://www.postgresql.org/docs/current/interactive/contrib.html
- http://www.postgresql.org/docs/current/interactive/pageinspect.html
- http://www.postgresql.org/docs/current/interactive/pgstattuple.html
- http://www.postgresql.org/docs/current/interactive/datatype.html