Hot Standby y Streaming replication
Table Of Contents
Dos de las características más importantes incluidas en la versión 9.0 de PostgreSQL que se lanzará a finales de verano del 2010 son Hot Standby (HS) y Streaming Replication (SR).
Estas dos características implementan en el núcleo de PostgreSQL lo necesario para instalar un sistema de replicación asincrónica maestro-esclavo (master-slave) en el que los nodos esclavos se pueden utilizar para realizar consultas de solo lectura. Un sistema de replicación de estas caracteristicas se podrá usar tanto para añadir redundancia a nuestras bases de datos, como para descargar de trabajo a nuestro servidor principal en lo referente a consultas de solo lectura.
NOTA: Este artículo está basado en la versión 9.0beta2 de PostgreSQL, todavia quedan por ajustar algunos detalles para la versión 9.0 final, pero lo más importante ya está implementado y decidido. Cuando la versión 9.0 sea lanzada, actualizaremos este artículo si es necesario.
Antes de seguir hablando en detalle sobre como configurar y usar HS y SR, tenemos que explicar ciertos conceptos fundamentales para poder entender como este sistema de replicación funciona.
Conceptos básicos
-
Ficheros WAL: PostgreSQL utiliza los denominados ficheros WAL (Write Ahead Log / REDO) para guardar toda la información sobre las transacciones y cambios realizados en la base de datos. Los ficheros WAL se utilizan para garantizar la integridad de los datos grabados en la base de datos. También se utilizan para reparar automáticamente posibles incosistencias en la base de datos después de una caida súbita del servidor.
Estos ficheros tienen un nombre único y un tamaño por defecto de 16MB y se generan en el subdirectorio pg_xlog que se encuentra en el directorio de datos (
$PGDATA) usado por PostgreSQL. El número de ficheros WAL contenidos enpg_xlogdependerá del valor asignado al parámetrocheckpoint_segmentsen el fichero de configuraciónpostgresql.conf.Los ficheros WAL generados en
pg_xlogse reciclan continuamente y en un sistema muy ocupado solo tendremos disponibles en pg_xlog los últimos cambios ocurridos en la base de datos durante el periodo de tiempo registrado en los ficheros WAL existentes enpg_xlog.Los ficheros WAL se pueden archivar automáticamente como copia de seguridad ó para usarlos con PITR - Point in Time Recovery. Para activar el archivo automático de ficheros WAL hay que definir los parámetros
wal_level,archive_modeyarchive_commandenpostgresql.conf. Un fichero WAL se archivará antes que sea reciclado enpg_xlog, pero no antes de que tenga registrado 16MB de información en el mismo. -
Transferencia de registros a nivel de ficheros (file-based log shipping): O lo que es lo mismo, transferencia de ficheros WAL completos (16MB de registros) entre servidores de bases de datos.
-
Transferencia de registros a nivel de registros (record-based log shipping): Transferencia de registros WAL sobre la marcha entre servidores de bases de datos. Esto es lo que hace Streaming Replication.
-
Replicación/transferencia asincrónica: Cuando los datos se transfieren de un sistema A a otro B, sin esperar por el “acuse de recibo” de B antes de hacer disponibles en A los datos replicados . En un sistema de replicación asincrónico puede existir un cierto retraso ó demora en la disponibilidad de los datos en el sistema esclavo.
-
Replicación/transferencia sincrónica: Cuando los datos se transfieren de un sistema A, a otro B, y A espera el “acuse de recibo” de B antes de hacer disponibles en A los datos replicados. En un sistema de replicación sincrónico, todos los datos disponibles en el maestro están disponibles en los esclavos.
Streaming replication (SR)
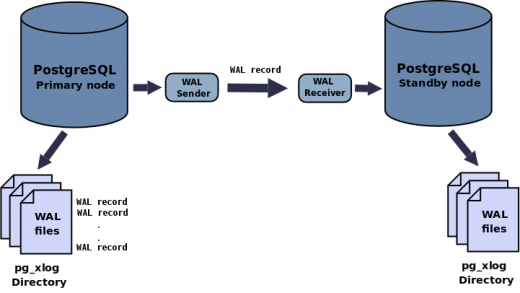
Esta nueva funcionalidad nos permite transferir asincrónicamente registros WAL sobre la marcha (record-based log shipping) entre un servidor maestro y uno/varios esclavos. SR se configura mediante los parámetros primary_conninfo en el fichero recovery.conf y max_wal_senders, wal_sender_delay y wal_keep_segments en postgresql.conf.
En la práctica un proceso denominado receptor WAL (WAL receiver) en el servidor esclavo, se conecta mediante una conexion TCP/IP al servidor maestro. En el servidor maestro existe otro proceso denominado remitente WAL (WAL sender) que es el encargado de mandar los registros WAL sobre la marcha al servidor esclavo.
A continuación teneis un gráfico explicativo de como SR funciona:
Hot Standby (HS)
Esta nueva funcionalidad nos permite acceder en modo de solo-lectura a todos los datos disponibles en el servidor esclavo a donde estamos replicando nuestras bases de datos. HS se configura mediante los parametros hot_standby y max_standby_delay en postgresql.conf
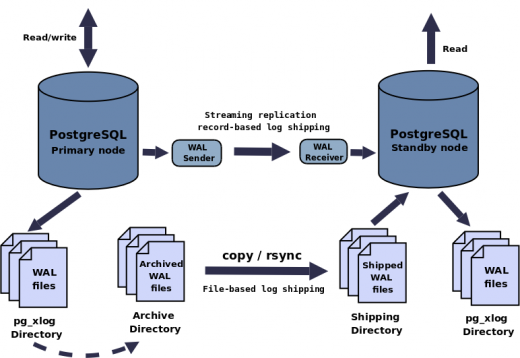
A continuación teneis un gráfico explicativo de como HS funciona usando SR y transferencia de ficheros WAL:
Introduccion al concepto de replicación implementado en el núcleo de PostgreSQL
El tipo de replicación incluido en el núcleo de PostgreSQL está basado en la transferencia de registros WAL entre servidores. Esta transferencia se puede realizar registro a registro (record-based log shipping) ó en ficheros WAL completos (file-based log shipping).
Si usamos solamente SR tendremos que tener cuidado que los ficheros WAL en el servidor maestro no sean reciclados antes de ser transferidos al servidor esclavo. Y si transferimos solamente ficheros WAL sin utilizar SR, perderemos las últimas transacciones registradas en el servidor maestro en caso de caida del servidor maestro. Es por esto que para tener un sistema más robusto, se suelen usar los dos métodos conjuntamente.
Una replicación basada en la transferencia de registros WAL significa que se replicaran absolutamente todas las bases de datos y cambios que realicemos en el servidor maestro. Si lo que necesitamos es replicar solamente algunas de las bases de datos existentes en el maestro ó algunas tablas, tendremos que usar otro tipo de replicación.
Para configurar un sistema HS usando SR y transferencia de registros WAL, tendremos que realizar lo siguiente:
- Configurar el acceso automático mediante llaves SSH entre el servidor maestro y el esclavo.
- Configurar uno de los servidores como maestro
- Activar el archivo de ficheros WAL en el servidor maestro
- Activar la transferencia al servidor esclavo de ficheros WAL archivados en el maestro
- Configurar el acceso necesario en el maestro para que el servidor esclavo pueda conectarse via SR
- Arrancar el servidor maestro
- Realizar una copia de seguridad ‘base’, mediante el mismo procedimiento que se utiliza con PITR
- Restaurar en el servidor esclavo la copia de seguridad ‘base’ realizada en el maestro
- Configurar el servidor esclavo en recuperación continua de registros WAL
- Configurar el servidor esclavo como nodo Hot Standby
- Crear un fichero recovery.conf en el esclavo
- Activar el uso de SR en el esclavo
- Activar el uso de ficheros WAL transferidos, en el proceso de restauración
- Arrancar el servidor esclavo
Todo este proceso es más fácil de lo que parece. A continuación vamos a ver paso por paso como hacerlo.
Configuración de todos los componentes
Lo primero que tenemos que hacer es instalar dos servidores lo más idénticos posibles. En nuestro caso hemos instalado dos servidores Ubuntu 10.04 server idénticos e instalados con la misma configuración.
A continuación tenemos que instalar la versión PostgreSQL 9.0 en los dos servidores. Podeis utilizar el método de instalación que más os guste, yo soy de la antigua escuela y PostgreSQL lo suelo instalar desde el código fuente y compiladolo yo mismo.
En nuestro caso hemos instalado PostgreSQL 9.0 en el directorio /usr/local/pgsql-9.0/ de nuestros sistemas.
Lo primero que tenemos que hacer en el servidor maestro (server01 - 10.1.1.100) y en el esclavo (server02 - 10.1.1.101) es crear los directorios que vamos a utilizar en nuestro sistema de replicación:
root@server01:~# mkdir -p /var/pgsql/data
root@server01:~# mkdir -p /var/pgsql/wal_arch
root@server01:~# chown -R postgres:postgres /var/pgsql
root@server01:~# chmod -R 0700 /var/pgsql
root@server02:~# mkdir -p /var/pgsql/data
root@server02:~# mkdir -p /var/pgsql/wal_arch
root@server02:~# mkdir -p /var/pgsql/wal_shipped
root@server02:~# chown -R postgres:postgres /var/pgsql
root@server02:~# chmod -R 0700 /var/pgsql
Después configuramos el acceso mediante llaves SSH entre el maestro y el esclavo. Más información sobre este tema se puede encontrar en el artículo “Combinando SSH, cron y at”.
Primero tenemos que generar nuestras claves pública y privada en el servidor maestro y el esclavo:
root@server01:~# su - postgres
postgres@server01:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/postgres/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/postgres/.ssh/id_rsa.
Your public key has been saved in /home/postgres/.ssh/id_rsa.pub.
The key fingerprint is:
97:56:f8:a7:c3:71:90:5d:54:0f:e1:71:98:00:a6:ea postgres@server01
root@server02:~# su - postgres
postgres@server02:~$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/postgres/.ssh/id_rsa):
Created directory '/home/postgres/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/postgres/.ssh/id_rsa.
Your public key has been saved in /home/postgres/.ssh/id_rsa.pub.
The key fingerprint is:
51:8b:37:7c:e3:8f:27:4e:48:c5:df:eb:c2:bb:c1:04 postgres@server02
A continuación creamos el fichero /home/postgres/.ssh/authorized_keys en el maestro con el contenido del fichero /home/postgres/.ssh/id_rsa.pub en el esclavo. Y viceversa, creamos el fichero /home/postgres/.ssh/authorized_keys en el esclavo con el contenido del fichero /home/postgres/.ssh/id_rsa.pub en el maestro.
El siguiente paso es inicializar el cluster PostgreSQL en el servidor maestro:
postgres@server01:~$ /usr/local/pgsql-9.0/bin/initdb -D /var/pgsql/data --locale=C --encoding=UTF8
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale C.
The default text search configuration will be set to "english".
fixing permissions on existing directory /var/pgsql/data ... ok
creating subdirectories ... ok
selecting default max_connections ... 100
selecting default shared_buffers ... 32MB
creating configuration files ... ok
creating template1 database in /var/pgsql/data/base/1 ... ok
initializing pg_authid ... ok
initializing dependencies ... ok
creating system views ... ok
loading system objects' descriptions ... ok
creating conversions ... ok
creating dictionaries ... ok
setting privileges on built-in objects ... ok
creating information schema ... ok
loading PL/pgSQL server-side language ... ok
vacuuming database template1 ... ok
copying template1 to template0 ... ok
copying template1 to postgres ... ok
WARNING: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the -A option the
next time you run initdb.
Success. You can now start the database server using:
/usr/local/pgsql-9.0/bin/postgres -D /var/pgsql/data
or
/usr/local/pgsql-9.0/bin/pg_ctl -D /var/pgsql/data -l logfile start
Antes de arrancar el servidor maestro por primera vez tenemos que actualizar el fichero postgresql.conf con ciertos parámetros.
En este artículo solamente mostraremos los parametros mínimos que se necesitan para nuestro sistema de replicación. Más información sobre otros parametros extras que tambien se pueden modificar para controlar diversos aspectos de la replicación se pueden consultar en la documentación de PostgreSQL.
En un sistema que se vaya a utilizar en producción, tendremos que cambiar tambien otros parámetros, especialmente los que definen como se va a usar la memoria. Una introducción mínima a este tema se puede encontrar en el artículo “Configuración básica de PostgreSQL”.
listen_addresses = '10.1.1.100'
wal_level = hot_standby
archive_mode = on
archive_command = '/usr/local/pgsql-9.0/bin/archive_wal.sh -P %p -F %f'
max_wal_senders = 5
wal_keep_segments = 10
Los parámetros que hemos cambiado en el maestro son:
- listen_addresses: Con este parámetro definimos la IP por la que podremos acceder via TCP/IP a postgreSQL.
- wal_level: Este parámetro define cuanta información se grabará en los ficheros WAL generados. Se pueden utilizar tres valores, minimal, archive y hot_standby. En nuestro caso utilizamos el valor hot_standby, porque vamos a utilizar esta funcionalidad.
- archive_mode: Con este parámetro activamos el archivo de ficheros WAL en el maestro.
- archive_command: Con el comando definido en este parámetro, copiamos los ficheros WAL a archivar al directorio /var/pgsql/wal_arch en el servidor maestro y transferimos los ficheros WAL archivados, al directorio /var/pgsql/wal_shipped en el servidor esclavo.
- max_wal_senders: Con este parámetro definimos el número máximo de conexiones que se pueden realizar desde servidores esclavos al servidor maestro via SR (1 por servidor esclavo)
- wal_keep_segments: Este parámetro define el número máximo de ficheros WAL que mantendremos sin reciclar en el servidor maestro en el caso que SR se retrase en la replicación de datos. Si utilizamos ademas de SR, transferencia de ficheros WAL, este parámetro no es tan importante de configurar.
El script archive_wal.sh en nuestro artículo es un script en BASH simple y minimo. Mediante el mismo copiamos los archivos WAL a archivar al directorio /var/pgsql/wal_arch en el maestro y al directorio /var/pgsql/wal_shipped en el esclavo.
En un sistema de producción este script deberia de comprobar y tener en cuenta posibles fallos ó errores que se pueden producir en el día a día. En un próximo artículo veremos como hacer este script más robusto.
#!/bin/bash
CHMOD="/bin/chmod"
COPY="/bin/cp"
SCP="/usr/bin/scp"
# Directorio usado por PostgreSQL para generar los ficheros WAL
PG_XLOG_DIR="/var/pgsql/data/pg_xlog"
# Directorio usado por PostgreSQL para archivar los ficheros WAL
PG_WAL_ARCH_DIR="/var/pgsql/wal_arch"
# Servidor PostgreSQL esclavo
STANDBY_SERVER="10.1.1.101"
# Directorio en servidor esclavo donde transferimos los ficheros
# WAL archivados en el servidor maestro.
PG_WAL_SHIPPED="/var/pgsql/wal_shipped"
NO_ARGS=0
E_OPTERROR=65
# ########################################
# ########################################
#
# Function archive_wal()
#
# ########################################
# ########################################
archive_wal(){
if $COPY -dp $ABSOLUTE_PATH $PG_WAL_ARCH_DIR/$WAL_FILE
then
$CHMOD 400 $PG_WAL_ARCH_DIR/$WAL_FILE
$SCP $PG_WAL_ARCH_DIR/$WAL_FILE $STANDBY_SERVER:$PG_WAL_SHIPPED
else
sleep 1
exit 1
fi
}
# ########################################
# ########################################
# Script invoked with no command-line args?
# ########################################
# ########################################
if [ $# -eq "$NO_ARGS" ]
then
help
exit $E_OPTERROR
fi
# ########################################
# ########################################
# Getting command options
# ########################################
# ########################################
while getopts "P:F:" Option
do
case $Option in
P)
ABSOLUTE_PATH=$OPTARG;;
F)
WAL_FILE=$OPTARG;;
esac
done
shift $(($OPTIND - 1))
# ########################################
# ########################################
# Sanity check
# ########################################
# ########################################
if [ -z $ABSOLUTE_PATH ]
then
echo "Error: Absolute path not defined"
echo
exit $E_OPTERROR
fi
if [ -z $WAL_FILE ]
then
echo "Error: WAL filename not defined"
echo
exit $E_OPTERROR
fi
archive_wal
exit 0
#
# EOF
Como vamos a utilizar Streaming Replication (SR), tenemos que definir tambien en el fichero pg_hba.conf del servidor maestro una linea que permita el acceso del proceso receptor WAL (WAL receiver) al servidor maestro.
host replication all 10.1.1.101 255.255.255.255 trust
Para facilitar las cosas en este artículo, hemos definido un acceso que no use SSL para encriptar el tráfico y que no necesite el uso de ninguna clave de acceso.
En un sistema en producción yo personalmente utilizaria SSL para encriptar el tráfico y el uso de certificados para la autentificación del servidor esclavo. Todo dependerá del nivel de seguridad que se quiera implementar. Más informacion sobre el tema se puede encontrar en el artículo “PostgreSQL y el uso de SSL”.
Si utilizais un sistema de autentificación que necesite clave de acceso, por ejemplo “md5”, tendreis que definir un fichero .pgpass en los servidores esclavos.
En estos momentos ya estamos preparados para arrancar el servidor maestro:
postgres@server01:~$ /usr/local/pgsql-9.0/bin/pg_ctl -D /var/pgsql/data -l /var/pgsql/data/logserver.log start
Una vez arrancado el servidor maestro vamos a realizar una copia de seguridad ‘base’ mediante el mismo procedimiento que se utiliza con PITR. A continuación, restauraremos esta copia de seguridad ‘base’ en el servidor esclavo
postgres@server01:~$ /usr/local/pgsql-9.0/bin/psql template1 -c "SELECT pg_start_backup('copia base inicial')"
pg_start_backup
-----------------
0/1000020
(1 row)
postgres@server01:~$ tar -cvf /home/postgres/pg_base_backup.tar /var/pgsql/data/
postgres@server01:~$ /usr/local/pgsql-9.0/bin/psql template1 -c "SELECT pg_stop_backup()"
pg_stop_backup
----------------
0/10000D8
(1 row)
postgres@server01:~$ scp /home/postgres/pg_base_backup.tar 10.1.1.101:~/tmp/
postgres@server01:~$ ssh postgres@10.1.1.101 "cd / && tar -xvf /tmp/pg_base_backup.tar"
postgres@server01:~$ ssh postgres@10.1.1.101 "rm /var/pgsql/data/postmaster.pid"
Para terminar, lo único que nos queda hacer es modificar el fichero postgresql.conf y crear el fichero recovery.conf en el servidor esclavo.
En el fichero postgresql.conf definiremos los siguientes parámetros:
listen_addresses = '10.1.1.101'
hot_standby = on
Los parámetros que hemos cambiado en el esclavo son:
- listen_addresses: Con este parámetro definimos la IP por la que podremos acceder via TCP/IP a postgreSQL.
- hot_standby: Para definir que este servidor esclavo se podrá utilizar para realizar consultas de solo lectura.
Y en el fichero /var/pgsql/data/recovery.conf definiremos los siguientes parámetros:
standby_mode = 'on'
primary_conninfo = 'host=10.1.1.100 port=5432 user=postgres'
trigger_file = '/var/pgsql/data/pg_failover_trigger'
restore_command = 'cp /var/pgsql/wal_shipped/%f "%p"'
Los parámetros que definimos en este fichero son:
- standby_mode: Este parámetro define que el servidor no saldrá del modo de recuperación y continuará probando la restauración continua de información WAL
- primary_conninfo: Este parámetro define el servidor maestro usado por SR para recoger registros WAL
- trigger_file: Con este parámetro se define un fichero que en caso de crearse/existir sacará al servidor esclavo del modo “hot standby” y de recuperación continua.
- restore_command: Con este parámetro definimos el comando a utilizar, si es necesario, para restaurar los ficheros WAL que se encuentran en /var/pgsql/wal_shipped
Una vez realizado estos cambios podemos arrancar postgreSQL en el servidor esclavo.
postgres@server02:~$ /usr/local/pgsql-9.0/bin/pg_ctl -D /var/pgsql/data -l /var/pgsql/data/logserver.log start
Y comprobar como el servidor maestro y el esclavo contienen los mismos datos.
postgres@server01:~$ /usr/local/pgsql-9.0/bin/psql
psql (9.0beta2)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=#
postgres@server02:~$/usr/local/pgsql-9.0/bin/psql
psql (9.0beta2)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=#
Después de ejecutar ciertos comandos en el servidor maestro, podemos comprobar como los cambios son replicados automáticamente al esclavo.
postgres@server01:~$ /usr/local/pgsql-9.0/bin/psql
psql (9.0beta2)
Type "help" for help.
postgres=# CREATE DATABASE test001;
CREATE DATABASE
postgres=# \c test001
You are now connected to database "test001".
test001=# CREATE TABLE test01 (id bigint, value bigint, primary key (id));
NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "test01_pkey" for table "test01"
CREATE TABLE
test001=# INSERT INTO test01 (id, value) VALUES (1,1);
INSERT 0 1
postgres@server02:~$ /usr/local/pgsql-9.0/bin/psql
psql (9.0beta2)
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+----------+-----------+-------+-----------------------
postgres | postgres | UTF8 | C | C |
template0 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | C | =c/postgres +
| | | | | postgres=CTc/postgres
test001 | postgres | UTF8 | C | C |
(4 rows)
postgres=# \c test001
You are now connected to database "test001".
test001=# \d test01
Table "public.test01"
Column | Type | Modifiers
--------+--------+-----------
id | bigint | not null
value | bigint |
Indexes:
"test01_pkey" PRIMARY KEY, btree (id)
test001=# SELECT * from test01 ;
id | value
----+-------
1 | 1
(1 row)
test001=#
A partir de este momento ya solo os queda disfrutar de vuestro sistema de replicación.
Tareas de administración y mantenimiento
Una vez que todo está funcionando, tendremos que mantener el sistema y administrarlo en caso de fallo del servidor maestro. Las tareas que tendremos que implementar/realizar serán:
- Limpiar el directorio donde se archivan los ficheros WAL en el servidor maestro, borrando los ficheros WAL antiguos que no se necesiten.
- Limpiar el directorio a donde se transfieren los ficheros WAL en el servidor esclavo, borrando los ficheros WAL antiguos que no se necesiten.
- Activar automáticamente el servidor esclavo como nuevo servidor maestro en caso de fallo del servidor maestro en uso.
- Monitorizar el estado de la replicación para saber el retraso del servidor esclavo en relación al maestro
Estas tareas las trataremos en próximos artículos. En el momento de escribir este artículo, y como ya hemos dicho, la versión 9.0 está todavía en fase beta y aun quedan algunos detalles por pulir. Además se están preparando por la comunidad algunos programas que ayudarán a la implementación de algunas de estas tareas de mantenimiento.
Enlaces: