Integridad referencial con PostgreSQL
La integridad referencial es una funcionalidad disponible en las bases de datos relacionales que garantiza la coherencia de datos entre relaciones aparejadas.
Bajo mi punto de vista, es una de las características básicas y más importantes que una base de datos nos puede proporcionar y siempre se deberia de usar para garantizar la integridad de los datos.
Es increible ver como muchisimos proyectos de sotfware libre que usan una base de datos, no usan para nada la integridad referencial disponible en la base de datos. Muchos de ellos intentan implementar cierta integridad en la aplicación. Esto es lo mismo que intentar inventar la rueda de nuevo y por supuesto está a la merced de posibles fallos de programación en la aplicación.
La integridad referencial se define con el uso combinado de claves primarias (primary keys) ó claves candidatas (candidate key) y clave foráneas (foreign key).
Las claves primarias y candidatas están formadas por valores únicos y una clave foránea solamente puede estar asociada a una de estas para garantizar la existencia de un solo valor correcto. Las claves candidatas se pueden definir creando un índice único (CREATE UNIQUE INDEX ….) en la columna pertinente.
Para poder usar esta funcionalidad es importante tener nuestra base de datos normalizada para:
- Evitar la redundancia de los datos.
- Evitar problemas de actualización de los datos en las tablas.
- Proteger la integridad de los datos
Nada mejor que un simple ejemplo para ver como podemos implementar la teoria con unos simples comandos.
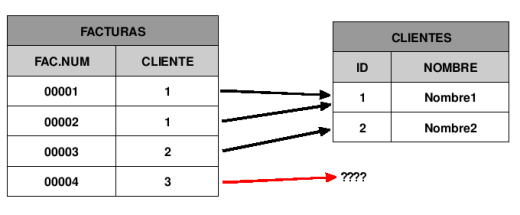
En nuestro ejemplo tenemos dos tablas. Una de clientes, con dos atributos, un número identificador y un nombre. Y otra tabla para facturas con el número de factura y el número de cliente.
Si no utilizaramos integridad referencial, que ocurriria si:
- ¿Intentamos insertar una factura con un número de cliente que no existe?
- ¿Borramos un cliente que tiene una factura asignada?
La respuesta es sencilla, las dos operaciones se podrian realizar sin problemas y tendriamos un sistema con unos datos en los que no podriamos confiar por la falta de consistencia de los mismos.
Esto lo podemos arreglar con dos sencillas operaciones, creamos una clave primaria en el atributo ID de la tabla clientes y una clave foránea en el atributo CLIENTE de la tabla facturas.
Esto lo podemos hacer cuando definamos la tabla ó con los siguientes comandos para la clave primaria:
ALTER TABLE clientes ADD CONSTRAINT cliente_pk PRIMARY KEY (id);
Y para la foránea, por ejemplo:
ALTER TABLE facturas ADD CONSTRAINT clientes_id_fk FOREIGN KEY (cliente)
REFERENCES clientes(id) MATCH FULL ON DELETE RESTRICT ON UPDATE CASCADE;
Esto seria suficiente para implementar integridad referencial en las dos tablas de nuestro ejemplo. Si intentamos hacer algo ilegal con nuestros datos, la base de datos nos lo prohibirá y nos dará un error.
postgres=# SELECT * from clientes;
id | nombre
----+-----------
1 | nombre 1
2 | nombre 2
(2 rows)
postgres=# SELECT * from facturas;
facnum | cliente
--------+---------
0001 | 1
0002 | 1
0003 | 2
(3 rows)
postgres=# SELECT facturas.facnum, clientes.nombre AS cliente
FROM clientes
JOIN facturas ON (clientes.id = facturas.cliente)
ORDER BY facnum;
facnum | cliente
--------+-----------
0001 | nombre 1
0002 | nombre 1
0003 | nombre 2
(3 rows)
postgres=# INSERT INTO facturas (facnum,cliente) VALUES ('0004',3);
ERROR: insert or update on table "facturas" violates foreign key constraint
"clientes_id_fk"
DETAIL: Key (cliente)=(3) is not present in table "clientes".
postgres=# DELETE FROM clientes WHERE id = 1;
ERROR: update or delete on table "clientes" violates foreign key constraint
"clientes_id_fk" on table "facturas"
DETAIL: Key (id)=(1) is still referenced from table "facturas".
postgres=# UPDATE clientes SET id = 3 where id = 1;
UPDATE 1
postgres=# SELECT * from clientes;
id | nombre
----+-----------
2 | nombre 2
3 | nombre 1
(2 rows)
postgres=# SELECT * from facturas;
facnum | cliente
--------+---------
0003 | 2
0001 | 3
0002 | 3
(3 rows)
postgres=# SELECT facturas.facnum, clientes.nombre AS cliente
FROM clientes
JOIN facturas ON (clientes.id = facturas.cliente)
ORDER BY facnum;
facnum | cliente
--------+-----------
0001 | nombre 1
0002 | nombre 1
0003 | nombre 2
(3 rows)
Hay tres parametros cuando definimos una clave foránea que son muy importantes y que definen como la base de datos se va a comportar para salvaguardar la integridad de nuestros datos. Estos parametros son:
- MATCH tipo
- ON DELETE accion
- ON UPDATE accion
En donde tipo puede tener estos valores:
- FULL: No permite que una columna tenga el valor NULL en una clave foránea compuesta por varias columnas
- SIMPLE: Permite que una columna tenga el valor NULL en una clave foránea compuesta por varias columnas
Y accion puede tener estos valores:
- NO ACTION: Produce un error indicando que un DELETE ó UPDATE creará una violación de la clave foránea definida.
- RESTRICT: Produce un error indicando que un DELETE ó UPDATE creará una violación de la clave foránea definida.
- CASCADE: Borra ó actualiza automáticamente todas las referencias activas
- SET NULL: Define las referencias activas como NULL
- SET DEFAULT: Define las referencias activas como el valor por defecto (si está definido) de las mismas
En nuestro ejemplo hemos definido que ninguna columna de nuestra clave foránea puede ser NULL, que no se pueda borrar una clave foránea con referencias activas y que en caso de actualizar el valor de una clave foránea, se actualicen tambien todas las referencias a la misma automáticamente.
Esto es todo en esta introducción a la integridad referencial en nuestra base de datos.
Para una información detallada y completa sobre el tema, consultar estos enlaces: