Identificando problemas de rendimiento
Table Of Contents
Este artículo está basado e inspirado en el tutorial titulado “Performance Whack-a-Mole II” que Josh Berkus dio en Ottawa durante la conferencia PGCon2009.
Si estais administrando pequeños sistemas sin muchos datos ó usuarios, probablemente nunca tendreis que pensar en muchos de los temas que se tratan en este artículo. Pero si teneis ó vais a tener a vuestro cargo sistemas más complejos, os vendrá bien la lectura de lo que se trata aquí. Aunque el artículo está centrado en las bases de datos PostgreSQL, mucha de la información contenida en el mismo es perféctamente válida para sistemas que usen otras bases de datos.
Cualquier administrador de bases de datos ha oido, al menos una vez durante su vida profesional, la siguiente afirmación, “la base de datos va muy lenta”. Cuando os llegue este momento tendreis que analizar vuestro sistema e intentar identificar cuales son las causas de los problemas de rendimiento que teneis. En este artículo vamos a tratar de explicar técnicas y procedimientos generales que nos pueden ayudar a identificar y aislar los posibles problemas que pueden afectar a el rendimiento global de los sistemas con los que trabajemos.
Para empezar podemos citar algunas reglas generales que suelen cumplirse cuando tenemos problemas de rendimiento en nuestro sistema:
- Tu sistema tendrá el rendimiento del peor de sus componentes
- La mayoría de los problemas de rendimiento no suelen estar en la base de datos.
- Menos del 10% de los problemas de rendimiento de tu sistema son los causantes de una reducción del rendimiento de aproximadamente el 90%.
- En todo momento y normalmente, solo es posible observar e identificar el problema de rendimiento más grande del momento.
- Diferentes tipos de aplicaciones tienen diferentes problemas característicos y modos de arreglarlos.
A continuación vamos a dar una introducción a los diferentes tipos de componentes y diferentes tipos de sistemas con los que nos podemos encontrar, así como las técnicas, procedimientos y herramientas que podemos usar para intentar identificar problemas de rendimiento.
Componentes de nuestro sistema
Nuestro sistema está formado por numerosos componentes y todos y cada uno de estos componentes influyen en mayor ó en menor medida en el rendimiento de nuestro sistema.
A continuación teneis un gráfico que ilustra los posibles diferentes componentes de nuestro sistema de forma jerárquica.
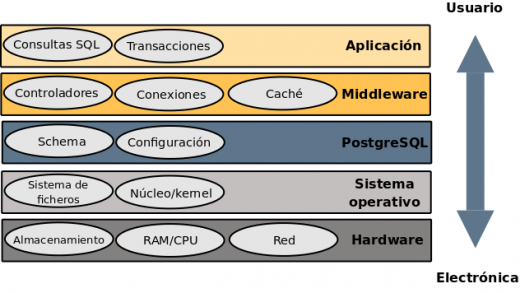
Generalmente, cuando tengamos un problema de rendimiento empezaremos la búsqueda de la causa en la capa inferior (hardware) e iremos subiendo progresivamente a la siguiente capa superior hasta localizar el problema.
Tipos de aplicaciones
Desde el punto de vista de un administrador de bases de datos, existen a grandes rasgos tres tipos de aplicaciones:
- Aplicaciones web (Web)
- Aplicaciones de procesamiento de transacciones en linea (OLTP)
- Almacenes de datos (data warehouse - DW)
A continuación teneis las características generales diferenciadoras más importantes de estos tipos de aplicaciones:
Aplicaciones web (Web)
- Base de datos más pequeña que el total de RAM
- El 90% ó más de las consultas, son consultas simples
- Limitada por la CPU
- Los problemas típicos que se suelen dar son: cache, pooling, tiempos de conexión
Aplicaciones de procesamiento de transacciones en linea (OLTP)
- Base de datos ligeramente más grande que el total de RAM y hasta 1 TB
- El 20%-40% de las consultas son pequeñas consultas que actualizan datos
- Unas pocas transacciones grandes y consultas de datos complejas
- Limitada por CPU ó I/O
- Los problemas típicos son: bloqueos (locks), cache, transacciones,
- velocidad de escritura, registros (logs)
Almacenes de datos (data warehouse - DW)
- Base de datos muy grande (de 100GB a 100TB)
- Consultas grandes y complicadas para generar informes
- Actualización de datos en grandes bloques (bulk load)
- Limitada por I/O ó RAM
- Los problemas típicos son: escaneos sequenciales (seq scans), recursos, consultas inefectivas, actualizaciones masivas (bulk load)
Técnicas y procedimientos
Una vez que hemos visto los posibles componentes que pueden formar parte de nuestro sistema y los diferentes tipos de aplicaciones con los que nos podemos encontrar, vamos a pasar a ver procedimientos y técnicas que podemos utilizar para identificar y arreglar problemas de rendimiento en nuestro sistema.
A continuación teneis una estrategia que podeis seguir para localizar problemas:
-
Recolección de información:
Esta es una de las fases más importantes y cruciales, en ella tenemos que intentar entender que está haciendo el sistema que vamos a arreglar, que componentes se están utilizando y como estos componentes funcionan e interactuan entre si. Tendremos que identificar de que tipo de aplicación se trata, que intenta hacer la aplicación, como utiliza la base de datos, que tipo de problemas están teniendo los usuarios, etc. En definitiva, obtener una vision general de como el sistema hace las cosas e intentar identificar posibles areas problemáticas del mismo.
-
Comprobación general de la configuración básica del sistema:
En esta fase realizaremos un recorrido general sobre la configuración del sistema para comprobar en que estado se encuentra. Comprobaremos la configuración del hardware y el sistema operativo, de PostgreSQL, middleware ,si existe, y de la aplicacion/es usando el sistema.
-
Identificación de posibles problemas:
En esta fase empezaremos a analizar los diferentes componentes del sistema para tratar de identificar posibles problemas que afecten al rendimiento. Probablemente ya hayamos identificado varios problemas durante el punto 1) y 2)
-
Arreglo del mayor problema identificado:
Una vez identificado el mayor problema, tendremos que buscar la solución del mismo.
-
Repetición:
Cuando el primer problema más importante esté arreglado volver a repetir los puntos 3) y 4) hasta que estemos contentos con el resultado.
Vamos a ver que tipo de información deberiamos de recolectar y que deberiamos comprobar en los diferentes componentes del sistema que tengan problemas. Como ya hemos dicho, generalmente empezaremos con el hardware e iremos subiendo progresivamente a las capas superiores, aunque esto dependerá del sistema y algunas veces cambiaremos el orden.
A continuación teneis información sobre los componentes y los puntos más comunes que se deberian comprobar:
Hardware
Servidores
- Modelo de CPU, velocidad de la CPU, numero de CPUs disponibles, arquitectura, uso de las mismas
- Cantidad de RAM, velocidad de la RAM, configuración de la misma
- ¿Estamos usando servidores dedicados para la base de datos y para los demas componentes?
Almacenamiento
- Tipos de interfaces (controladores, RAID)
- Tipos de discos, tamaño y velocidad de los mismos
- Configuración del Array/SAN
- ¿Estamos usando una configuración RAID adecuada?
- ¿Estamos usando cache de escritura (segura/con baterias)?
- ¿Estamos usando todos los dispositivos disponibles (discos, canales)?
Red
- Tipo de red y capacidad de la misma
- Tarjetas de red usadas, modelos
- Configuración de los conmutadores y enrutadores (switch/router)
- ¿Estamos usando una red dedicada entre la aplicación y la base de datos?
- ¿Estamos usando conexiones redundantes y balanceo del tráfico de red?
Sistema operativo
Sistema operativo
- Tipo de SO, versión, parches aplicados, modificaciones locales
- Información sobre los controladores de hardware usados
- ¿Estamos utilizando la última versión del kernel y parches disponibles?
- ¿Estamos usando la última versión de los controladores de hardware?
- ¿Qué recursos estamos usando?¿Estamos usando servidores dedicados?
- ¿Tenemos otras aplicaciones usando los recursos del servidor?
Sistema de ficheros
- Tipo de sistema de ficheros que estamos utilizando
- Localización de los ficheros del sistema operativo, PostgreSQL y otras aplicaciones
- Configuración del sistema de fichero utilizado
- ¿Está xlog en un disco dedicado?
- ¿Estamos utilizando una configuración no estandard del sistema de fichero usado?
PostgreSQL
Schema
- Diseño, modelo de datos
- Tamaño de los datos
- Particionado de los datos, tablespaces
- Indices usados
- Procedimientos almacenados en uso
Configuración
- ¿Qué cambios se han realizado en la configuración estandard?
- ¿Se ejecutan trabajos de mantenimiento (VACUUM/ANALYZE)?
- ¿Con que frecuencia y configuración se ejecutan los trabajos de mantenimiento?
- Comprobar los parametros más importantes, unos valores orientativos que se podrian usar serian :
- shared_buffers = 25-30% RAM
- work_men = [1] 512k, [2] 2MB, [3] 128MB
(nunca mas de RAM/num.conexiones)
- maintenance_work_mem = 1/16 RAM
- checkpoints_segments = [1] 8, [2][3] 16-64
- wal_buffers = [1] 1MB, [2][3] 8MB
- effective_cache_size = 2/3 RAM
- random_page_cost = 2.0
- autovacuum = on [1][2]
- vacuum_cost_delay = 20ms [1][2]
- vacuum/analyze despues de inicializar/actualizar
una gran cantidad de datos.
[1] Aplicacion Web
[2] Tipica app. OLTP
[3] Tipica app. datawarehouse
Middelware
Controladores,Conexiones,Cache
- Tipo y versión usada de los controladores DB
- Método de conexión usada, pooling usado, configuración del pooling
- Método de cache usado, herramientas usadas para administrarlo, versión y configuración
- Software ORM utilizado y versión
- ¿Estamos utilizando las ultimas versiones de los controladores, cache, etc?
- ¿Estamos utilizando pooling y cache?
- ¿Usamos consultas preparadas?
Aplicación
Consultas SQL,Transacciones
- Tipo de aplicación
- Modelo y tipo de transacciones
- Tipos y numeros de consultas
- ¿Cómo funciona la aplicación, como se usa, tiene un tráfico constante ó momentos con cargas máximas?
- ¿Estamos usando procedimientos almacenados?
Herramientas
Existen numerosas herramientas que se pueden utilizar para intentar localizar diferentes problemas en nuestro sistema. Dependiendo de la parte del sistema que estemos analizando usaremos unas u otras.
No vamos a profundizar en como se utilizan estas herramientas en este artículo, esto lo dejamos para otros artículos mas especializados. A continuación teneis una relación de herramientas que podriamos utilizar con las diferentes partes del sistema. Hardware y sistema operativo
Herramientas del sistema operativo
Estas herramientas suelen ser muy fáciles de usar, no suelen afectar al resto del sistema mientras que las utilizamos y nos pueden ayudar a monitorizar y obtener estadísticas de como esta funcionando el hardware y nuestro sistema en general.
- ps: Nos permite ver los procesos postgreSQL que se están ejecutando en nuestro servidor. Nos da una idea de la cantidad de procesos concurrentes y el uso de CPU y memoria que tienen. Tambien nos permite identificar consultas que se han colgado, que estan bloqueadas ó que llevan ejecutandose mucho tiempo.
- pg_top: Este programa nos suministra mucha de la información que ps nos da y otra relacionada exclusivamente con postgreSQL.
- mpstat: Nos proporciona información sobre el uso de todas las CPU de nuestro sistema. Podemos encontrar los recursos de CPU que se están usando, si estamos usando todas las CPU disponibles ó si tenemos problemas de ‘cambio de contexto’(context-switch)
- vmstat, free: Nos permite ver el uso que estamos haciendo de la memoria. Podemos ver si la memoria está saturada, si podemos tener más información en cache ó si estamos utilizando el swap de nuestro sistema.
- iostat: Para monitorizar el uso de los dispositivos de almacenamiento de nuestro sistema. Podemos ver si el subsistema I/O está saturado, si alguno de los dispositivos está causando un embotellamiento del resto de los dispositivos, ó si tenemos subidas puntuales del tráfico en los discos debido a los ‘checkpoint’ generados por PostgreSQL.
- sar: Se puede utilizar para obtener información de la actividad del sistema durante un periodo de tiempo definido.
Test de rendimientos
Los test de rendimientos suelen ser muy intrusivos y suelen afectar al resto del sistema mientras que se ejecutan. Por esto, no siempre se pueden usar en sistemas en producción que están funcionando con ciertos problemas pero que tienen que seguir funcionando aunque su rendimiento no sea el óptimo. Permiten comparar resultados entre sistemas con mismo hardware y sistema operativo.
- dd: Lee y escribe datos de manera sequencial
- bonnie++: Para comprobar el rendimiento y posibles problemas con I/O. Comprueba entre otras cosas, la velocidad de busqueda (seek) y escritura aleatoria del sistema.
- IOzone: Comprueba las velocidades de diferentes operaciones.
PostgreSQL
Views y funciones de sistema
Muy fáciles de usar, su uso no afecta al rendimiento de nuestro sistema. Nos proporcionan información sobre lo que está ocurriendo internamente en nuestra base de datos y nos pueden ayudar a identificar problemas relacionados con el diseño/modelo de datos, consultas, procedimientos almacenados y bloqueos.
- pg_stat_database, pg_database_size(): Para conseguir estadísticas de tráfico generales, números de conexiones, número de transacciones válidas (commits) y abortadas (rollback), proporción de aciertos de datos en cache, tamaño de la base de datos.
- pg_tables, pg_relation_size(): Para obtener información sobre las tablas de nuestra base de datos, cuantas existen, si tienen disparadores, índices ó reglas asociadas, y el tamaño de las tablas e índices de la base de datos
- pg_stat_activity: Para comprobar la actividad actual en la base de datos, consultas en ejecución, bloquedas, conexiones concurrentes, ociosas (idle), etc
- pg_locks: Para descubrir y comprobar conflictos con bloqueos.
- pg_stat[io]_user_tables, pg_stat[io]_user_indexes: Para comprobar la actividad relacionada con las tablas y los índices de nuestra base de datos, informacion sobre ‘seq scans’, I/O, etc
- pg_stat_bgwriter: Para comprobar estadísticas relacionadas con el proceso ‘background writer’ encargado de los ficheros WAL.
- pg_stat_user_functions (8.4): Para obtener los tiempos de ejecución de nuestras funciones, diferenciando entre tiempos de llamada y ejecución del código.
- pg_stat_statements (contrib 8.4): Este módulo ‘contrib’ se puede utilizar para obtener una relación de consultas en ejecución junto con información sobre las más frecuentes y las más lentas
PostgreSQL logs, pgfouine y auto-explain
No hay nada como un buen fichero log para obtener información sobre lo que ha ocurrido en nuestro sistema.
- pg_log: Existen multitud de opciones en el fichero de configuración postgresql.conf para activar/desactivar los datos que nos interese registrar. La información obtenida mediante el log de postgreSQL se podrá analizar para obtener información en el caso de tener problemas.
- pgfouine: Se puede utilizar para calcular estadísticas generales de las consultas enviadas a la base de datos. Las consultas más frecuentes y más lentas no serán un misterio despues de utilizar este producto.
- auto-explain (8.4): Registra en el fichero log de postgreSQL la información sobre ‘explain plans’ de las consultas que queramos. Se puede activar/desactivar dinámicamente.
Explain analyze
El comando SQL ‘explain analyze [consulta SQL]’ se puede utilizar con consultas lentas para obtener información sobre las causas de la falta de velocidad. Muchas veces podremos arreglar la causa rapidamente y otras nos dará información sobre posibles causas a investigar.
El resultado de este comando es un arbol invertido de nodos el cual deberiamos de empezar a leer de abajo hacia arriba. Habria que empezar a buscar el nodo más bajo con problemas e intentar interpretar el resultado de manera integral/global, ya que algunos nodos se pueden ejecutar en paralelo e influenciarse mútuamente.
Algunas de las cosas que se deberian de comprobar y buscar en el resultado del comando ‘Explain analyze’ son:
- Estimaciones erroneas del número de filas en una tabla
- ‘Index scans’ y ‘seq scans’ lentos
- Ordenación de datos en disco en vez de en memoria
Test de rendimientos
- pgbench: Test de rendimiento muy simple con el que se puede comprobar el subsistema I/O y la velocidad a la que se procesan las conexiones. No comprueba bloqueos, computación de datos ó ‘query planning’. Util para demostrar problemas importantes de hardware ó en el sistema operativo.
- DBT2: Test muy completo y costoso de ejecutar. Basado en TPCC es un completo test de rendimiento para sistemas OLTP.
- DBT3: Nuevo test OLTP + DW
- Otros: pgUnitTest, EAstress, BenchmarkSQL
Middelware / aplicación
Existen también una serie de herramientas que se pueden utilizar a nivel del middelware/aplicación que nos pueden ayudar a obtener información valiosa que nos ayude a localizar nuestro problema. Enumeramos solo algunas de las más importantes:
- Herramientas para servidores de aplicaciones: Se pueden usar para analizar los tiempos de respuesta, monitorización de la actividad de la base de datos, y monitorización del uso del cache.
- Simulacion de cargas: Herramientas como lwp y reproductores de información contenida en ficheros log.
- Herramientas para detectar bugs: Valgrind, MDB, GDB
Problemas de rendimiento típicos
A continuación teneis una visión general sobre los problemas de rendimiento más comunes.
Problemas con el subsistema I/O
Cuando tenemos problemas con el subsistema I/O, lo más normal es que las CPUs estén subutilizadas, tengamos memoria disponible y al menos un dispositivo de almacenamiento con el I/O saturado.
Estos problemas suelen darse en sistemas del tipo OTLP y DW (data warehouse), bases de datos muy grandes ó bases de datos con un ratio de escritura muy alto.
Las causas comunes de este tipo de problemas son:
- Problemas con el hardware/software encargado del subsistema I/O
- Mala configuración del subsistema I/O
- No suficiente memoria
- Demasiados datos demandados por la aplicación
- Schema no óptima, falta de índices ó particionamiento de datos
Problemas con CPU
Cuando tenemos problemas con el uso de la CPU, lo más normal es que estemos usando el 90% ó más de la capacidad de CPU disponible, tengamos memoria disponible y el subsistema I/O noe esté saturado.
Estos problemas suelen darse en sistemas del tipo Web y OTLP, bases de datos con una gran cantidad de consultas de lectura ó consultas en las que se realizan cálculos complejos.
Las causas comunes de este tipo de problemas son:
- Demasiadas consultas
- Insuficiente cache/pooling
- Demasiados datos demandados por la aplicación
- Consultas mal construidas
- Schema no óptima, falta de índices
Problemas de bloqueos
Cuando tenemos este tipo de problema, lo más normal es que ni la base de datos, ni la aplicacion esten trabajando al máximo, pero tengamos muchas consultas con grandes periodos de espera, un alto índice de ‘cambio de contexto’ (context switching), y pg_locks mostrando consultas bloqueadas.
Estos problemas suelen darse en sistemas del tipo OTLP y DW (data warehouse), ó trabajos que usen bloqueos pesimistas ó procedimientos almacenados.
Las causas comunes de este tipo de problemas son:
- Ejecuciones de larga duracion de transacciones ó procedimientos almacenados
- Cursores mantenidos durante mucho tiempo
- Bloqueos pesimistas en vez de optimistas ó bloqueos definidos por los usuarios
- Gestión mala de transacciones
- Varias configuraciones de buffers en postgresql.conf con valores muy bajos
- Límites en la escalabilidad de PostgreSQL en sistemas SMP
Problemas con la aplicación
Cuando tenemos este tipo de problema, lo más normal es que la base de datos no esté trabajando al máximo, pero el uso de la memoria y/o la CPU en el servidor de aplicación estén al máximo.
Estos problemas suelen darse en sistemas J2EE
Las causas comunes de este tipo de problemas son:
- No tenemos suficientes servidores de aplicaciones
- Demasiados datos/consultas demandados por la aplicación
- Mala configuración del cache/pooling
- Problemas con los controladores DB
Más información
Bueno esto es todo en este artículo, la experiencia es vuestra mejor aliada y con el tiempo os será cada vez más fácil identificar los posibles problemas de rendimiento de vuestro sistema.
Teneis la presentación completa con algunos ejemplos practicos y el video de la misma, en ingles, en esta dirección: http://www.pgcon.org/2009/schedule/track/Tutorial/188.en.html