OpenAI/Whisper, Machine learning and speech recognition on my HomeLab
Table Of Contents
Introduction
A couple of days ago I read in the specialized press an article1 about how the University of Oslo had implemented an automatic video subtitle creation service. They had used a system called OpenAI Whisper2.
I don’t know why, maybe because I also work at the University of Oslo, but this time I got curious and decided to investigate a little more on the subject. “Artificial intelligence”3 and “Machine learning”4 are terms that we are constantly hearing in recent times and often sound like science fiction to many.
According to OpenAI, Whisper is an automatic voice recognition system and has been trained with more than 680,000 hours of audio multilingual and multitasking compiled from the internet. It can be used to transcribe audio in a multitude of languages and to translate these audios into English.
Whisper uses the Python programming language, the machine learning library PyTorch5, the NumPy6 numerical analysis library, the deep learning model of HuggingFace7 Transformers8 and FFmpeg9 to encode and convert different audio formats and video.
I am a neophyte in the field and I only have fairly basic theoretical knowledge of how these systems work. I have no practical experience in how to program them internally. Could I install a system like this in my home laboratory without using a lot of resources? Could I get a practical result from its use? Let’s see it in this article.
About Whisper internals
According to the project website, “Whisper is a general-purpose speech recognition model. It is trained on a large dataset of diverse audio and is also a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.”
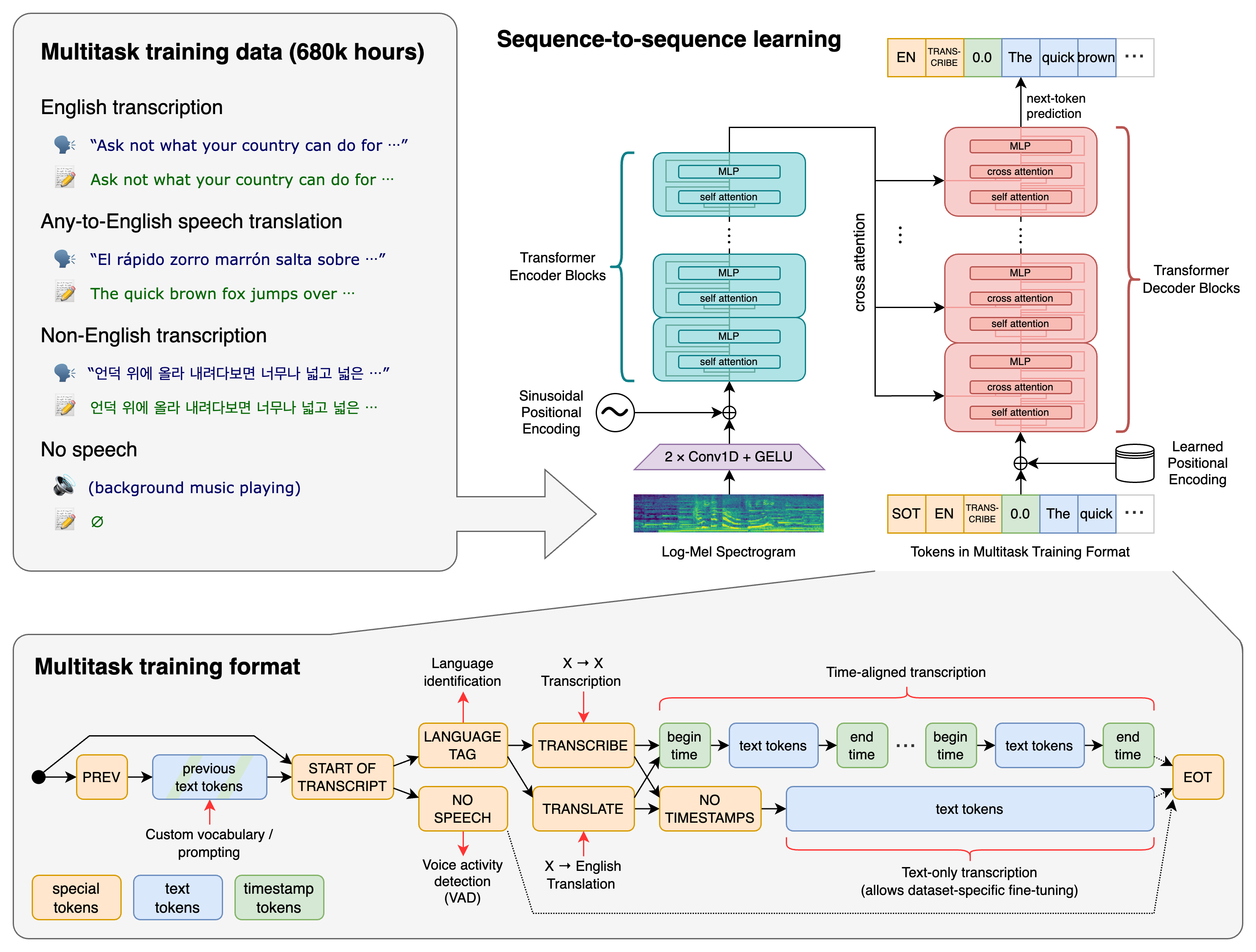
“A Transformer sequence-to-sequence model is trained on various speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection. All of these tasks are jointly represented as a sequence of tokens to be predicted by the decoder, allowing for a single model to replace many different stages of a traditional speech processing pipeline. The multitask training format uses a set of special tokens that serve as task specifiers or classification targets.”
That’s a very short explanation, The paper “Robust Speech Recognition via Large-Scale Weak Supervision”10 has the full explanation of how the system works.
Installation and configuration
The first thing I did was to create a virtual machine running Ubuntu 22.04.2 LTS in the KVM server at my homeLab. I didn’t know how many resources I would need so I assigned 24G RAM and 10x vCPUs to this VM. The KVM server has 96G RAM in total and an “AMD Ryzen™ 9 3900X 3.8GHz”11 with 12 CPU cores and 24 threads, so the machine had plenty of resources still available.
Ubuntu 22.04.2 comes with Python 3.10.6 so this version was more than enough for running Whisper. FFmpeg and PIP were not installed by default so I installed them:
sudo apt update && sudo apt install ffmpeg python3-pip
Then and according to the short documentation in the OpenAI/Whisper github pages12 I installed Whisper via PIP. This command installed whisper and all the Python modules needed by Whisper
pip install -U openai-whisper
Was this all?, in theory I had everything I needed installed and ready to be used.
Use and Performance
To begin this section I have to say that the introduction section of this article has been generated by OpenAI Whisper, this was my test case. I created an audio file with my voice and the introduction in Spanish. Then I used Whisper, first to transcribe the audio to text and see if it recognized my “Andalusian accent”13 when I speak Spanish, and second to translate the audio into English, before copying and pasting the text without modifications into this article.
I must say that I am impressed with the result after so little effort on my part.
The introduction I read in Spanish into an audio file had 311 words and 1979 characters. The audio file had a duration of 2min 12s, a size of 2.4M and it was created with Audacity14:
rafael@server:~$ file introduction-es.mp3
introduction-es.mp3: MPEG ADTS, layer III, v1, 128 kbps, 44.1 kHz, JntStereo
rafael@server:~$ ls -lh
total 2,4M
-rw-rw-r-- 1 rafael rafael 2,4M Feb 28 13:28 introduction-es.mp3
The next thing I had to do was to use Whisper to generate the text transcription of the audio. I used the large model in whisper to get better results. The first time you run this command Whisper will download the model (around 2.87G) used to analyze the audio and generate the transcription.
rafael@test-whisper:~$ time whisper introduction-es.mp3 --model large --language es --task transcribe
real 11m34.645s
user 85m41.837s
sys 27m55.946s
It took 11m34s to finish, the Whisper process used 100% of all CPUs in the VM, 12G VIRT and 9G RES memory and used between 160-170W during the execution, around 0.032759 kWh to generate the transcription.
The result was perfect, Whisper created a perfect transcription15 of the audio I had produced in Spanish16. Impressive, taking into account that I use my Andalusian accent when creating the audio.
By default, Whisper creates trascription files in these formats JSON, SRT, TSV, TXT, VTT
rafael@test-whisper:~/art-es$ ls -lh
total 2.4M
-rw-rw-r-- 1 rafael rafael 2.4M Feb 28 12:29 introduction-es.mp3
-rw-rw-r-- 1 rafael rafael 12K Feb 28 12:42 introduction-es.mp3.json
-rw-rw-r-- 1 rafael rafael 2.7K Feb 28 12:42 introduction-es.mp3.srt
-rw-rw-r-- 1 rafael rafael 2.3K Feb 28 12:42 introduction-es.mp3.tsv
-rw-rw-r-- 1 rafael rafael 2.0K Feb 28 12:42 introduction-es.mp3.txt
-rw-rw-r-- 1 rafael rafael 2.6K Feb 28 12:42 introduction-es.mp3.vtt
For example, you could use one of these files to embedded the transcription as subtitles in a video.
The translation of the audio from Spanish to english was generated with this command:
rafael@test-whisper:~$ time whisper introduction-es.mp3 --model large --language es --task translate
real 9m3.948s
user 67m29.470s
sys 21m7.019s
It took less time to generate the translation, around 9min but the resource use was almost the same as under the transcription process.
The result as you can see in the “Introduction” section of this article was also very good and it was an accurate translation of the original in Spanish.
The performance was not great in my VM with 10x vCPUs, if the generation time grows linearly, it would have taken around 5,2hours to transcript a 1hour audio and around 4hours to translate the same audio.
I suppose this is the reason the University of Oslo is using the HPC17 infrastructure at the university to generate the transcriptions of the video production they have. They manage to produce 20 hours of transcriptions in 1 hour, that is impressive also, it would have taken my VM around 104hours and 17.68kWh of energy to do the same jobb.
Are you ready for some magic in your PC with minimal effort? OpenAI/Whisper is waiting for you.
Footnotes
-
Article: “Bygde tjeneste som sparer dem for 20 millioner i året: − Dette er ny og sjokkerende teknologi”:
https://www.digi.no/artikler/bygde-tjeneste-som-sparer-dem-for-20-millioner-i-aret-dette-er-ny-og-sjokkerende-teknologi-br/526412?key=6gN6miwh ↩︎ -
“OpenAI / Whisper”:
https://openai.com/research/whisper ↩︎ -
“Artificial intelligence”:
https://en.wikipedia.org/wiki/Artificial_intelligence ↩︎ -
“Machine learning”:
https://en.wikipedia.org/wiki/Machine_learning ↩︎ -
“PyTorch”:
https://en.wikipedia.org/wiki/PyTorch ↩︎ -
“NumPy”:
https://en.wikipedia.org/wiki/NumPy ↩︎ -
“Hugging face”:
https://huggingface.co/ ↩︎ -
“Transformers - Machine learning models”:
https://en.wikipedia.org/wiki/Transformer_(machine_learning_model) ↩︎ -
“FFmpeg”:
https://en.wikipedia.org/wiki/FFmpeg ↩︎ -
“Robust Speech Recognition via Large-Scale Weak Supervision”
https://cdn.openai.com/papers/whisper.pdf ↩︎ -
“AMD Ryzen™ 9 3900X 3.8GHz”:
https://www.amd.com/en/products/cpu/amd-ryzen-9-3900x ↩︎ -
“OpenAI/Whisper github”:
https://github.com/openai/whisper ↩︎ -
“Andalusian Spanish”:
https://en.wikipedia.org/wiki/Andalusian_Spanish
https://en.wikipedia.org/wiki/Andalusians ↩︎ -
“Audacity”:
https://www.audacityteam.org/ ↩︎ -
“Introduction in spanish - transcription”
https://e-mc2.net/files/whisper-introduction-in-es-transcription.txt ↩︎ -
“Introduction in spanish - original”
https://e-mc2.net/files/whisper-introduction-in-es-original.txt ↩︎ -
“HPC”:
https://en.wikipedia.org/wiki/High-performance_computing
https://www.uio.no/english/services/it/research/hpc/ ↩︎