Sistemas informaticos redundantes
Table Of Contents
En este articulo vamos a ver una introduccion de diferentes tecnicas que se utilizan para que los sistemas informaticos esten disponibles y se puedan acceder incluso cuando alguna parte del sistema falla.
Cuando se tienen sistemas criticos que tienen que estar disponibles y funcionando 24 horas al dia, 365 dias al año, hay que intentar minimizar los fallos que puedan afectar al funcionamiento normal del sistema. Fallos van a ocurrir, pero existen tecnicas y configuraciones que ayudan a tener sistemas redundantes, en los que ciertas partes pueden fallar sin que esto afecte al funcionamiento del mismo.
En un sistema informatico actual, existen muchos componentes necesarios para que este funcione, cuantos mas componentes, mas probabilidad tenemos de que algo falle. Estos problemas pueden ocurrir en el propio servidor, fallos de discos, fuentes de alimentacion, tarjetas de red, etc y en la infraestructura necesaria para que el servidor se pueda utilizar, componentes de red, acceso a internet, sistema electrico, ….
A continuacion vamos a ir comentando algunas de las tecnicas usadas para obtener sistemas redundantes. El grado de redundancia de un sistema, dependera de su importancia y del dinero que perdamos cuando el sistema no esta disponible por un fallo. No nos merecera la pena invertir en ‘redundancia’, si la inversion necesaria para tener un sistema redundante cuesta mas de lo que perderiamos en dinero, reputacion y horas de trabajo, si el sistema fallara.
Las tecnicas y configuraciones de las que hablamos a continuacion no son exclusivas de sistemas Linux. Se pueden aplicar en su gran mayoria a otros sistemas operativos y plataformas. Nosotros nos centraremos en Linux por ser el tema principal de “El rincon de Linux”.
Redundancia de componentes en el servidor
Los componentes redundantes mas normales en un servidor suelen ser, los discos, las tarjetas de red y las fuentes de alimentacion. Existen servidores con multiples CPUs que incluso siguen trabajando sin problemas con alguna CPU o modulo de memoria estropeado.
Discos
Los discos duros son los dispositivos donde se graban los datos. El fallo mas comun en un servidor es el fallo de un disco duro. Si el servidor tiene solamemente un disco y este falla, fallara el servidor al completo y no podremos acceder a los datos contenidos en el mismo. Existen por ello tecnicas que nos ayudan a minimizar este problema y a que el servidor siga funcionando y no pierda datos incluso cuando falle algun disco duro. Lo mas normal tambien, es que se puedan sustituir los discos que fallan sin necesidad de apagar el servidor (HotSwap)
La tecnica mas comun es la llamada RAID (redundant array of independent disks). Con esta tecnica creamos un conjunto de discos redundantes que nos pueden ayudar, tanto a aumentar la velocidad y el rendimiento del sistema de almacenamiento, como a que el sistema siga funcionando aunque algun disco falle. Existen implementaciones por software y hardware y diferentes configuraciones RAID, siendo las mas comunes RAID1, RAID5 y RAID10.
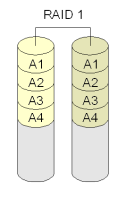
|
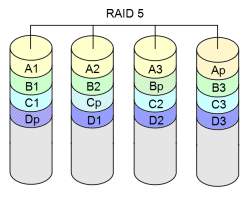
|
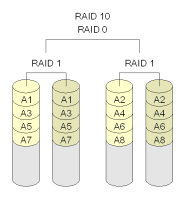
|
|---|
Tarjetas de red
La tarjeta de red es el dispositivo que permite al servidor comunicarse con el resto del mundo. Es por ello muy comun que los servidores tengan como minimo 2 tarjetas de red, para garantizar que esta comunicacion no se corte en caso de fallo de una de las tarjetas.
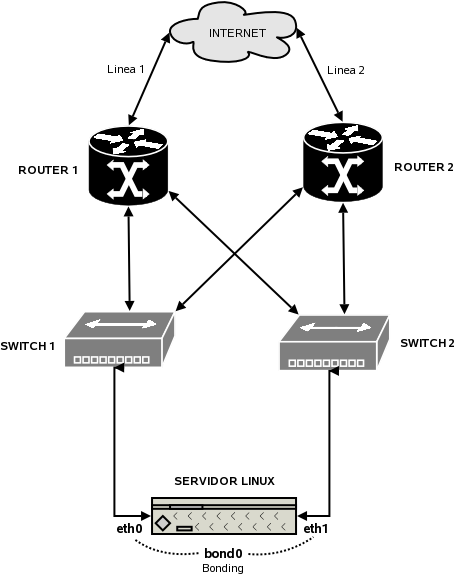
En Linux existe ademas una tecnica llamada ‘Bonding", por la cual podemos utilizar 2 o mas tarjetas de red como si fueran un unico dispositivo, sumando las capacidades de las mismas y teniendo redundancia en el caso que alguna de las tarjetas falle.
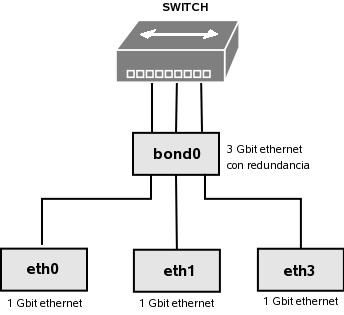
Fuentes de alimentacion
La fuente de alimentacion es la encargada de proporcionar electricidad al servidor. Tambien es comun que los servidores tengan 2 o mas fuentes de alimentacion conectadas a diferentes sistemas electricos, para garantizar el suministro en el caso que una de las fuentes o uno de los sistemas electricos fallen. Lo mas normal es que se puedan sustituir las fuentes de alimentacion que fallan sin necesidad de apagar el servidor (HotSwap). Otros componentes del sistema como routers, switches, cabinetes de discos, etc suelen utilizar la misma tecnica de redundancia.
Redundancia en el suministro electrico
Todo componente electrico, y un servidor no podia ser menos, necesita un suministro constante de electricidad para funcionar. Fallos en este suministro, aunque sean por periodos muy cortos de tiempo, tendra consecuencias catastrofales para nuestro sistema. Y no solo necesitamos un suministro constante, tambien necesitamos que no tenga subidas y bajadas brusquedas que puedan estropear componentes electronicos.
Para conseguir esto se pueden utilizar diferentes componentes segun el grado de proteccion que deseemos.
- SAI (UPS): Son baterias mas o menos avanzadas que se conectan entre el servidor y la fuente de suministro electrico. Garantizan un suministro constante y estable por un tiempo, dependiendo este de la capacidad de las mismas.
- Generadores electricos: Funcionan generalmente con diesel y se conectan entre los UPS y la red de suministro electrico. Solo entran en funcionamiento cuando el suministro se corta por mas de un determinado tiempo. Pueden suministrar electricidad por un tiempo indefinido siempre que tengan carburante en el tanque.
- Lineas independientes de suministros: En centros de datos grandes, se suelen tener al menos 2 conexiones diferentes e independientes a la red de suministro electrico.
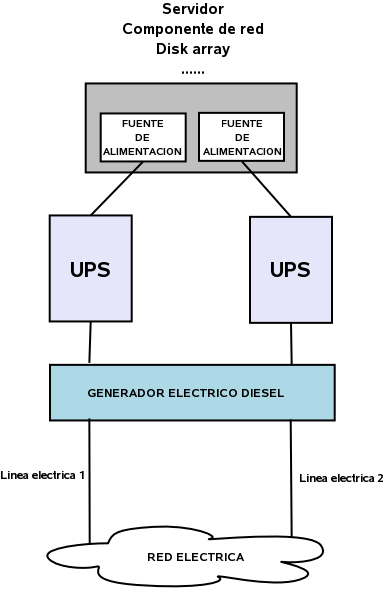
Si queremos redundancia en el sistema electrico, no hace falta decir que no solo los servidores tienen que tener dobles conexiones, routers, switches y en definitiva cualquier componente del sistema que utilice electricidad deberia de tener fuentes de alimentacion redundantes (conectadas). Como se suele decir, tu sistema solo sera tan seguro, estable y redundante como el componente mas debil del mismo. No es la primera vez, por ejemplo, que en un centro de datos, grupos de servidores con redundancia a todos lo niveles han quedado incomunicados porque estaban conectados a un switch que ha fallado por no tener un sistema redundante de suministro electrico.
Redundancia en los componentes de red
De nada sirve tener servidores con componentes duplicados y redundantes y un suministro electrico constante y equilibrarado si algunos de los componentes de la red fallan y no podemos acceder al servidor.
Los componentes mas normales en una red son:
- Routers (enrutador): Es un dispositivo que interconecta segmentos de red o redes enteras
- Switch (Conmutador): Es un dispositivo que interconecta dos o más segmentos de red
- Tarjeta de red o NIC: Es un dispositivo electrónico que permite a una DTE (Data Terminal Equipment), ordenador o impresora, acceder a una red y compartir recursos
- Cables de red: Para interconectar los diferentes componentes, existen muchos y variados tipos, siendo los mas comunes el cable de par trenzado y el de fibra optica
- Lineas de conexion: a la red de area amplia, WAN (por ejemplo Internet)
Cualquiera de estos componentes puede fallar, dejando al sistema incomunicado. Pero existen tecnicas para evitar que esto ocurra, lo que se suele hacer es configurar la red, para que al menos existan 2 caminos diferentes entre dos componentes A y B. En el grafico siguiente teneis un esquema, en el que podeis ver como configurar una red con redundancia doble desde el servidor hasta Internet. De esta manera se puede estropear un router, un switch y una tarjeta de red a la vez sin que perdamos conectividad. El mismo esquema se podria ampliar para tener redundancia triple o cuadruple de los componentes.
Redundancia de servidores, balanceo de cargas
Que ocurre si el suministro electrico funciona y la red funciona, pero nuestro servidor falla de tal manera que ninguno de los componentes redundantes que tiene pueda evitar el fallo y la caida del mismo. Existen diferentes tipos de configuraciones con varios servidores, que pueden ayudarnos con este problema. Son los llamados clusters, los hay de diferentes tipos, pero entre los mas usales esta el de balanceo de cargas con tolerancia a fallos. En este tipo de clusters, no solo no importa que uno o varios de los servidores deje de funcionar, sino que si necesitamos mas recursos para proporcionar un servicio, podemos incorporar nuevos servidores que incrementen la capacidad de proceso del cluster.
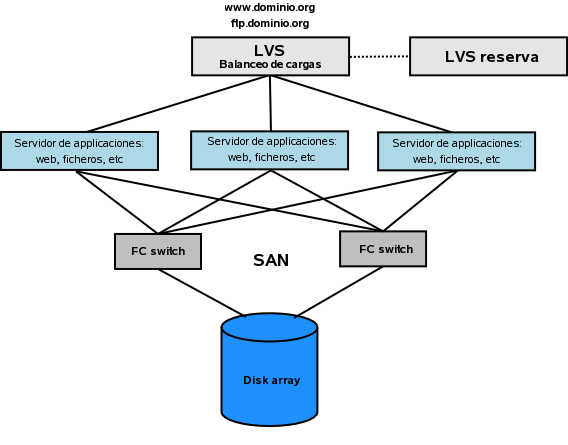
Los componentes mas importantes de este tipo de clusters son, los sistemas de almacenamiento unicos entre todos los servidores que proporcionan un servicio y el dispositivo de balanceo de cargas, el cual puede ser un hardware especifico para este trabajo o implemtarse por software en un servidor normal. El proyecto para Linux mas importante sobre este tema es el denominado Linux virtual server (LVS).
A continuacion teneis una serie de ejemplos de como se pueden organizar estos clusters, en donde el fallo de un servidor, no para el funcionamiento de un servicio. Cuando falla uno o varios servidores en el cluster, la capacidad de proceso del mismo se reduce, por lo que es importante tener siempre cierta capacidad sin usar para que en el caso de un fallo no se reduzca el tiempo de respuesta mucho.
Un ejemplo de cluster con balaceo de cargas conectado a un cabinete de discos (Disk array) para almacenar la informacion. Tipico uso para servidores de ficheros y web.
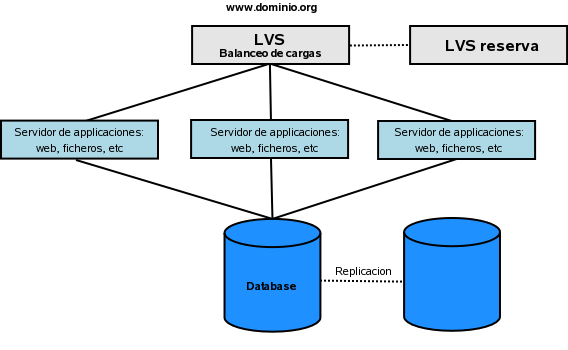
Un ejemplo de cluster con balaceo de cargas conectado una base de datos para almacenar la informacion. Tipico uso para web.
Un ejemplo de cluster con balaceo de cargas para un sistema de correo que proporcione IMAP y SMTP a sus usuarios.
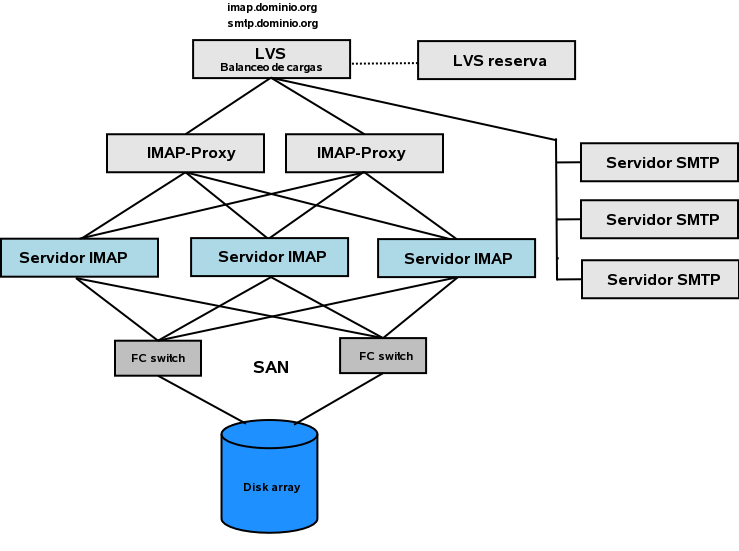
En fin, esto es todo lo que tenia pensado contar en esta introduccion a sistemas informaticos redundantes. Existe mucha informacion en Internet si quereis profundizar en el tema. Lo mas importante es tener conocimientos, de red y administracion y saber como funcionan los diferentes componentes de un sistema. La experiencia y estudios de estas materias os ayudaran a tener sistemas mas estables y redundantes.