Elasticsearch - Common maintenance tasks
Table Of Contents
Intro
If you have to administrate an Elasticsearch cluster, there are some common maintenance tasks that you will have to run to keep your data growth under control, backup your indexes and keep the cluster updated.
At the University of Oslo we have a 14 nodes Elasticsearch 5.x cluster (3 master + 2 clients + 4 SSD data+ 5 SAS data). We use it to manage, search, analyze, and explore our logs. It has around 100TB of total storage, around 1,300 indexes and we keep from 3 to 6-12 months of data per index type depending of the type of data they have.
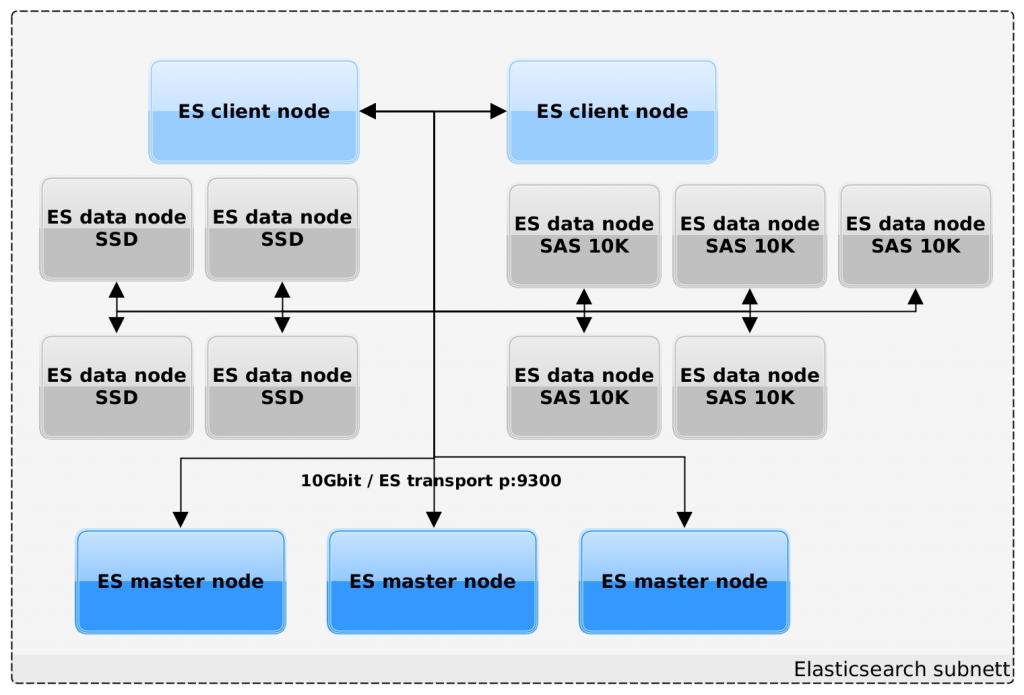
Some of the maintenance tasks we are running in our system are:
- Moving old indexes from the fast SSD nodes to the slower ARCHIVE nodes.
- Deleting old indexes from the ARCHIVE nodes base on a defined retention time.
- Taking snapshot backups of our indexes
- Deleting old snapshots backups
- Upgrades and restarts of nodes/elasticsearch via Ansible.
Many of these tasks can be done with a software distributed by Elastic and called “Curator”. This software has been available for a long time but you need the last version to work with, and take full advantage of the API functionality available with ElasticSearch 5.x. Old versions and examples of Curator available on the Internet will not work with ElasticSearch 5.x.
Moving old indexes
We do this to have only new data on the fast SSD nodes so the most common searches work faster and to not use expensive SSD storage with old data that is not accessed as often.
To move indexes between nodes we use the routing functionality in Elasticsearch. We have tagged our different data nodes with two tags, SSD and ARCHIVE. This is done in the Elasticsearch configuration file with these two parameters:
cluster.routing.allocation.awareness.attributes: group
node.attr.group: SSD
cluster.routing.allocation.awareness.attributes: group
node.attr.group: ARCHIVE
We have created a default index template where we define, among other things, that all new indexes created in the cluster get tagged with the SSD tag so they are created in the SSD nodes.
{
"order" : 0,
"template" : "*",
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"group" : "SSD"
}
}
},
"refresh_interval" : "5s",
"number_of_shards" : "2",
"number_of_replicas" : "1"
}
}
}
An finally we use the program Curator to change the tag of an index from SSD to ARCHIVE, when the index is older than 6 weeks. This will automatically activate the transfer of the index from the SSD to the ARCHIVE data nodes.
Curator has multiple parameters to configure what to do, read the documentation for full details. In our case, we have this entry in our crontab:
00 07 * * * root LOGFILE=/var/log/curator/archived-indices-$(/bin/date +\%Y_\%m_\%d-\%Hh\%Mm\%Ss) && \
/usr/bin/curator_cli --logfile $LOGFILE \
--logformat logstash \
--host es-client.example.net allocation \
--key group \
--value ARCHIVE \
--allocation_type include \
--filter_list \
'[{"filtertype":"age","source":"creation_date","direction":"older","unit":"weeks","unit_count":6}, \
{"filtertype":"pattern","kind":"prefix","value":"^\\.","exclude":"True"}]'
Deleting old indexes
Another important maintenance task in our system is the deletion of old indexes. The amount of data coming into the system is high and it is essential to delete old data to avoid using all the resources.
Our indexes have the following name pattern, <name-id-YYYY.WW> . We have a python script that connects to the Elasticsearch cluster, gets a list of all the indexes in the cluster and generates a cron file with a cron job for every
58 5 * * * root LOGFILE=/var/log/curator/name-id-$(/bin/date +\%Y_\%m_\%d-\%Hh\%Mm\%Ss) && \
/usr/bin/curator_cli \
--logfile $LOGFILE \
--logformat logstash \
--host es-client.example.org delete_indices \
--filter_list '[{"filtertype":"pattern","kind":"prefix","value":"name-id"},\
{"filtertype":"count","use_age":"True","source":"creation_date","count":12}]' && \
/bin/rm -f /var/log/curator/name-id-latest && \
/usr/bin/ln -s $LOGFILE /var/log/curator/name-id-latest
Taking snapshot backups
Elasticsearch has functionality to take backup (snapshots) of the indexes in the cluster.
First, you will have to create a “Snapshot Repository” in the cluster. You can define different types of repositories, we use the FS type (FileSystem) on a NFS disk available and mounted in all the Elasticsearch nodes.
Second, you can define a cron job and use “Curator” to generate a snapshot of all indexes in your cluster. In our case, we have this entry in our crontab:
00 23 * * * root LOGFILE=/var/log/curator/snapshots-daily-$(/bin/date +\%Y_\%m_\%d-\%Hh\%Mm\%Ss) && \
/usr/bin/curator_cli \
--host es-client.example.org snapshot \
--repository="Daily_snapshot" \
--wait_for_completion="true" \
--include_global_state="true" \
--filter_list '[{"filtertype":"age","source":"creation_date","direction":"older","unit":"days","unit_count":1}]' && \
/bin/rm -f /var/log/curator/snapshots-daily-latest && \
/usr/bin/ln -s $LOGFILE /var/log/curator/snapshots-daily-latest
To be fair, these snapshots can be very practical if you want or need to restore one or a few indexes, but I do not want to think how long it will take to restore a whole cluster in case of a mayor disaster. We are getting around 1.50-2.00GBps of data into the NFS disk when taking snapshots. Assuming that we could get the same speed when restoring data, we would need more than 72 hours for the 50TB of log data we have today.
Deleting old snapshots backups
Of course, if you take snapshots of your indexes, you should think about how long you want to keep this backups. We are keeping one week of snapshots and you can also use “Curator” to delete old snapshots. In our case, we have this entry in our crontab:
01 05 * * * root LOGFILE=/var/log/curator/snapshots-delete-$(/bin/date +\%Y_\%m_\%d-\%Hh\%Mm\%Ss) && \
/usr/bin/curator_cli \
--timeout=86400 \
--logfile $LOGFILE \
--host es-client.example.org delete_snapshots \
--repository="Daily_snapshot" \
--retry_interval=600 \
--retry_count=4 \
--filter_list '[{"filtertype":"age","source":"creation_date","direction":"older","unit":"days","unit_count":7}]' && \
/bin/rm -f /var/log/curator/snapshots-delete-latest && \
/usr/bin/ln -s $LOGFILE /var/log/curator/snapshots-delete-latest
Ansible playbooks for upgrades and restarts
From time to time, you need to execute some maintenance tasks in your Elasticsearch cluster to keep it updated or to change your configuration. When running these tasks you will have to restart Elasticsearch, and this means that the nodes will have to leave the cluster and join it again. The good news are that we can keep the cluster online and operational when running these maintenance tasks as long as we follow the right procedure.
The most common tasks involving the restart of the Elasticsearch process are:
(A) Minor Elasticsearch upgrade to a new version.
- Disable shard allocation on the cluster
- Run an index flush sync
- Upgrade Elasticsearch to a new version
- Restart the Elasticsearch process
- Wait for the node to rejoin the cluster
- Enable shard allocation on the cluster
- Wait for the Elasticsearch cluster state to become green
(B) Restart of Elasticsearch process to set a new configuration in production.
- Disable shard allocation on the cluster
- Run an index flush sync
- Restart the Elasticsearch process
- Wait for the node to rejoin the cluster
- Enable shard allocation on the cluster
- Wait for the Elasticsearch cluster state to become green
(C) Restart of Elasticsearch node to e.g. set in production a new kernel.
- Disable shard allocation on the cluster
- Run an index flush sync
- Stop Elasticsearch
- Restart the Elasticsearch node
- Wait for the Elasticsearch node to reboot
- Start Elasticsearch
- Wait for the node to rejoin the cluster
- Enable shard allocation on the cluster
- Wait for the Elasticsearch cluster state to become green
- We use Ansible to run these procedures on all our Elasticsearch nodes sequentially.
As you can see, the procedures to execute these tasks are very similar, they only differ from each other on a few steps. We use Ansible to run these procedures on all our Elasticsearch nodes sequentially. Here you have an example of Ansible code you can use to implement them. You should implement this code via Ansible roles/task and handlers to reuse all the common code.
For (A) you could use something like this:
- hosts: prod-all-nodes
# Important to run the procedure sequentially in all servers defined in prod-all-nodes
serial: 1
vars:
es_client_server: es-client.example.net
elasticsearch_version: 0.0.0-1
tasks:
# Disable shard allocation
- name: "Set cluster routing allocation to none {{ansible_hostname}}"
action: "shell curl -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"none\" }}'"
register: result
until: result.stdout.find('"acknowledged"') != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Index Flush sync
- name: "Index Flush sync - {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_flush/synced?pretty"
register: result
until: result.rc == 0
retries: 200
delay: 3
# Upgrade elasticsearch version via YUM
- name: "Elasticsearch upgrade on {{ansible_hostname}}"
yum: name=elasticsearch-{{ elasticsearch_version }} state=present enablerepo=elasticsearch-5.x
retries: 1000
delay: 10
# restart elasticsearch process
- name: "Elasticsearch restart {{ansible_hostname}}"
service: name=elasticsearch state=restarted
# Wait for Elasticsearch node to come back into cluster
- name: "Wait for elasticsearch running on node {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/nodes?h=name | tr -d ' ' | grep -E '^{{ansible_hostname}}' "
register: result
until: result.rc == 0
retries: 200
delay: 3
# Enable shard allocation
- name: "Set cluster routing allocation to all {{ansible_hostname}}"
action: "shell curl -s -m 2 -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"all\" }}'"
register: result
until: result.stdout.find("acknowledged") != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Wait until cluster status is green
- name: "Wait for green cluster status {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/health | cut -d ' ' -f 4"
register: result
until: result.stdout.find("green") != -1
retries: 5000
delay: 10
For (B) you can use the same code as (A) without the install block:
- hosts: prod-all-nodes
# Important to run the procedure sequentially in all servers defined in prod-all-nodes
serial: 1
vars:
es_client_server: es-client.example.net
tasks:
# Disable shard allocation
- name: "Set cluster routing allocation to none {{ansible_hostname}}"
action: "shell curl -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"none\" }}'"
register: result
until: result.stdout.find('"acknowledged"') != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Index Flush sync
- name: "Index Flush sync - {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_flush/synced?pretty"
register: result
until: result.rc == 0
retries: 200
delay: 3
# restart elasticsearch process
- name: "Elasticsearch restart {{ansible_hostname}}"
service: name=elasticsearch state=restarted
# Wait for Elasticsearch node to come back into cluster
- name: "Wait for elasticsearch running on node {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/nodes?h=name | tr -d ' ' | grep -E '^{{ansible_hostname}}' "
register: result
until: result.rc == 0
retries: 200
delay: 3
# Enable shard allocation
- name: "Set cluster routing allocation to all {{ansible_hostname}}"
action: "shell curl -s -m 2 -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"all\" }}'"
register: result
until: result.stdout.find("acknowledged") != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Wait until cluster status is green
- name: "Wait for green cluster status {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/health | cut -d ' ' -f 4"
register: result
until: result.stdout.find("green") != -1
retries: 5000
delay: 10
And for (C) you could use something like this:
- hosts: prod-all-nodes
# Important to run the procedure sequentially in all servers defined
# in prod-all-nodes
serial: 1
vars:
es_client_server: es-client.example.net
tasks:
# Disable shard allocation
- name: "Set cluster routing allocation to none {{ansible_hostname}}"
action: "shell curl -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"none\" }}'"
register: result
until: result.stdout.find('"acknowledged"') != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Index Flush sync
- name: "Index Flush sync - {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_flush/synced?pretty"
register: result
until: result.rc == 0
retries: 200
delay: 3
# Stop elasticsearch process
- name: "Elasticsearch stop {{ansible_hostname}}"
service: name=elasticsearch state=stopped
# Restart server
- name: "Restart server {{ansible_hostname}}"
command: "/sbin/shutdown -r +1"
async: 0
poll: 0
ignore_errors: true
# Wait for server to restart successfully
- name: "Wait for server {{ansible_hostname}} to restart successfully"
local_action:
wait_for host={{ansible_hostname}}
port=22
state=started
timeout=600
delay=120
sudo: false
# Start elasticsearch process
- name: "Elasticsearch start {{ansible_hostname}}"
service: name=elasticsearch state=started
# Wait for Elasticsearch node to come back into cluster
- name: "Wait for elasticsearch running on node {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/nodes?h=name | tr -d ' ' | grep -E '^{{ansible_hostname}}' "
register: result
until: result.rc == 0
retries: 200
delay: 3
# Enable shard allocation
- name: "Set cluster routing allocation to all {{ansible_hostname}}"
action: "shell curl -s -m 2 -XPUT http://{{ es_client_server }}:9200/_cluster/settings -d '{\"transient\" : {\"cluster.routing.allocation.enable\" : \"all\" }}'"
register: result
until: result.stdout.find("acknowledged") != -1
retries: 200
delay: 3
changed_when: result.stdout.find('"acknowledged":true') != -1
# Wait until cluster status is green
- name: "Wait for green cluster status {{ansible_hostname}}"
action: "shell curl -s -m 2 http://{{ es_client_server }}:9200/_cat/health | cut -d ' ' -f 4"
register: result
until: result.stdout.find("green") != -1
retries: 5000
delay: 10
Links:
- https://www.elastic.co/guide/en/elasticsearch/client/curator/current/index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/5.x/shard-allocation-fi…
- https://www.elastic.co/guide/en/elasticsearch/reference/current/rolling-upgrade…
- https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-snapsho…
- https://www.ansible.com/